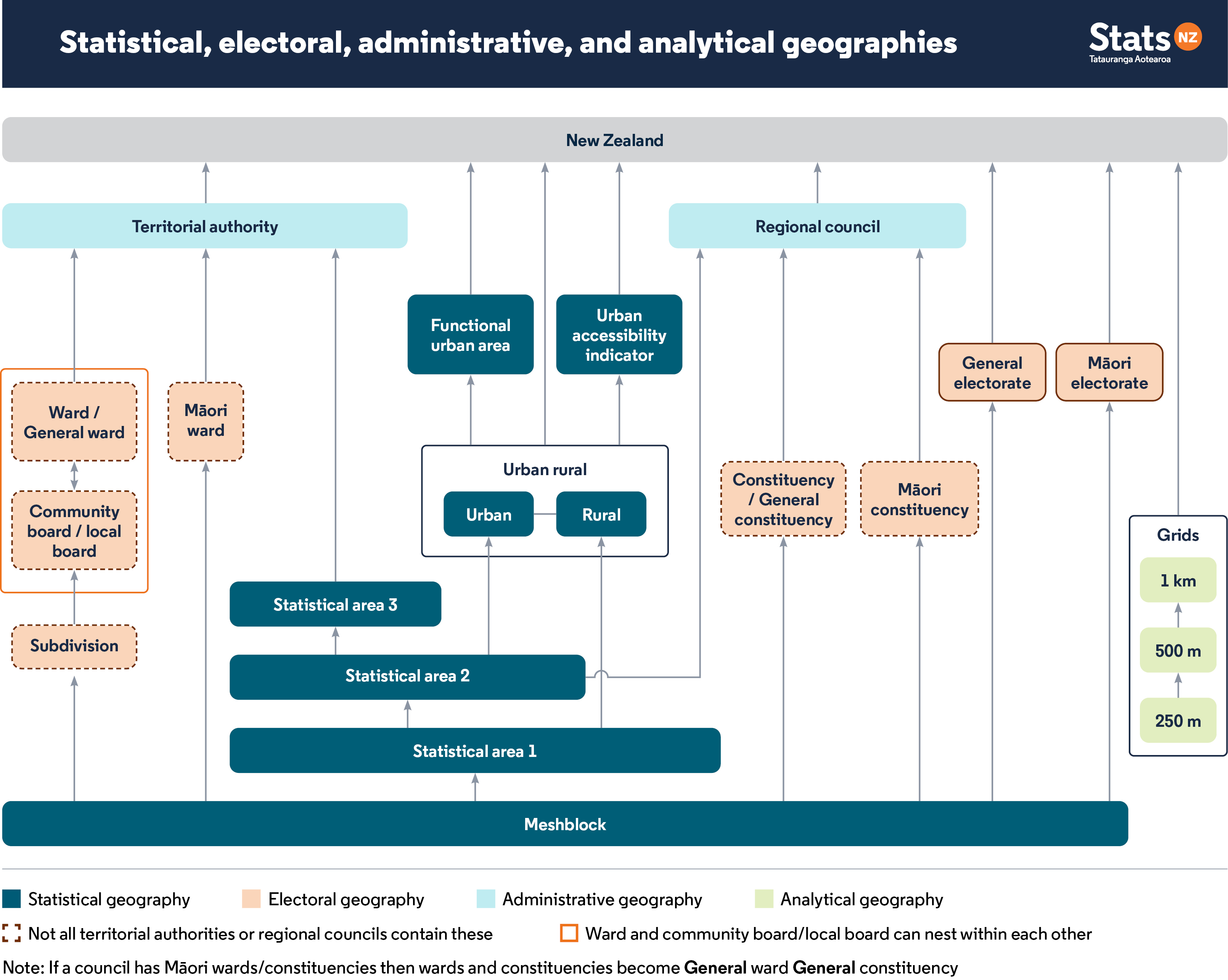
Chapter 7 “Linear Regression” from R for Health Data Science by Ewen Harrison and Riinu Pius (2021). This chapter is excellent, especially section 7.1.
In this practical you will be introduced to a suite of different models that will allow you to test a variety of research questions and hypotheses through modelling the associations between two or more spatially referenced variables.
In 2023 New Zealand scrapped an anti-smoking law that would mean a generational smoking bad for anyone born after 2008. So, here we will explore the factors that might affect smoking in New Zealand and see if they vary spatially.
This practical will walk you through the common steps that you should go through when building a regression model using spatial data to test a stated research hypothesis; from carrying out some descriptive visualisation and summary statistics, to interpreting the results and using the outputs of the model to inform your next steps.
Reading layer `territorial-authority-2018-generalised' from data source
`C:\Users\Andy\OneDrive - University College London\Teaching\Guest\Oxford_24\Spatial analysis of public health data\prac4_data\statsnzterritorial-authority-2018-generalised-SHP\territorial-authority-2018-generalised.shp'
using driver `ESRI Shapefile'
Simple feature collection with 68 features and 5 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 1067061 ymin: 4701317 xmax: 2523320 ymax: 6242140
Projected CRS: NZGD2000 / New Zealand Transverse Mercator 2000
census <-read_csv("prac4_data/SA1_census/Individual_part2_totalNZ-wide_format_updated_16-7-20.csv")
4.2.2 Wrangle
The .csv we have loaded contains all the data from the week 1 excel homework in a wide format - that means all the SA1s, SA2s and so are are a new row making a huge data file. Normally i would suggest a cool data sciency way to pull out our Territorial Authorities, however i can’t see anything that would work. For example, we could try and detect part of a string like “City” or “District” however they appear in other geographies.
So, until i can think or a better way we are resigned to subsetting by rows!
library(janitor)census_authorities <- census %>%slice(32413:32480) %>%clean_names()# or#census_authorities <- census[32413:32480,]%>%# clean_names()
Now in this case the data can be a little hard to read - we have over 350 columns! It might be sensible here to have a look at the excel document we downloaded in the week 1 homework to identify our our variables.
Let’s pull out the following variables from the 2018 data:
we’ll also try and include some spatial data (e.g. density of tobacco shops) at the very end…
However, because we are using spatial units and they may differ in size we should normalise our count data (everything but median income which is continous).
To do so i will use the “total” column for each variable, although you could also use population count
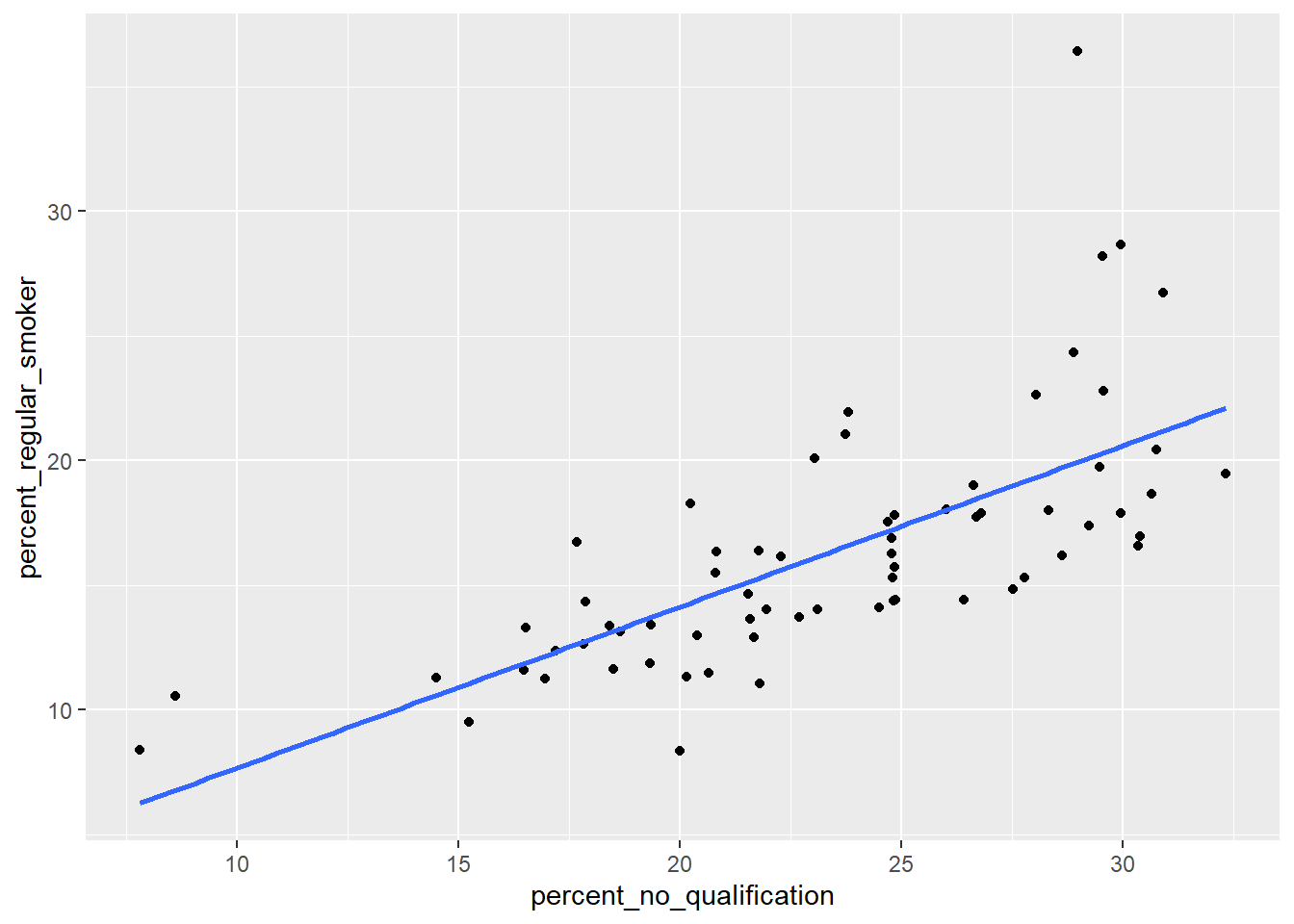
Here, I have plotted the percentage of regular smokers per territorial area against another variable in the dataset that I think might be influential…percentage with no qualification
Remember that my null hypothesis would be that there is no relationship between percentage of regular smokers and percentage with no qualification. If this null hypothesis was true, then I would not expect to see any pattern in the cloud of points plotted above.
As it is, the scatter plot shows that, generally, as the \(x\) axis independent variable (percentage with no qualification) goes up, our \(y\) axis dependent variable (percent of smokers) goes up. This is not a random cloud of points, but something that indicates there could be a relationship here and so I might be looking to reject my null hypothesis.
Some conventions - In a regression equation, the dependent variable is always labelled \(y\) and shown on the \(y\) axis of a graph, the predictor or independent variable(s) is(are) always shown on the \(x\) axis.
I have added a blue line of best-fit - this is the line that can be drawn by minimising the sum of the squared differences between the line and the residuals. The residuals are all of the dots not falling exactly on the blue line. An algorithm known as ‘ordinary least squares’ (OLS) is used to draw this line and it simply tries a selection of different lines until the sum of the squared differences between all of the residuals and the blue line is minimised, leaving the final solution.
As a general rule, the better the blue line is at summarising the relationship between \(y\) and \(x\), the better the model.
The equation for the blue line in the graph above can be written:
\[y_i = \beta_0 + \beta_1x_i + \epsilon_i\]
where:
\(\beta_0\) is the intercept (the value of \(y\) when \(x = 0\) - somewhere around 4 on the graph above);
\(\beta_1\) is sometimes referred to as the ‘slope’ parameter and is simply the change in the value of \(y\) for a 1 unit change in the value of \(x\) (the slope of the blue line) - reading the graph above, the change in the value of \(y\) reading between 20 and 15 on the \(x\) axis looks to be around a change from 15 to 17.5 on the \(y\) - about 0.5 per 1 unit value of \(x\).
\(\epsilon_i\) is a random error term (positive or negative) that should sum to 0 - essentially, if you add all of the vertical differences between the blue line and all of the residuals, it should sum to 0.
Any value of \(y\) along the blue line can be modeled using the corresponding value of \(x\) and these parameter values. Examining the graph above we would expect the percent smoking in an area where 26% of the population to not have any qualifications, to equal around 17%, but we can confirm this by plugging the \(\beta\) parameter values and the value of \(x\) into equation (1):
4+ (0.5*26) +0
[1] 17
4.3 Regression
In the graph above, I used a method called ‘lm’ in the stat_smooth() function in ggplot2 to draw the regression line. ‘lm’ stands for ‘linear model’ and is a standard function in R for running linear regression models. Use the help system to find out more about lm - ?lm
Below is the code that could be used to draw the blue line in our scatter plot. Note, the tilde ~ symbol means “is modeled by”.
Call:
lm(formula = percent_regular_smoker ~ percent_no_qualification,
data = .)
Residuals:
Min 1Q Median 3Q Max
-5.7961 -2.3344 -0.5826 1.1691 16.4704
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.20258 1.98667 0.605 0.547
percent_no_qualification 0.64634 0.08289 7.798 6.1e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 3.588 on 66 degrees of freedom
Multiple R-squared: 0.4795, Adjusted R-squared: 0.4716
F-statistic: 60.8 on 1 and 66 DF, p-value: 6.097e-11
4.3.1 Interpretation
In running a regression model, we are effectively trying to test (disprove) our null hypothesis. If our null hypothesis was true, then we would expect our coefficients to = 0.
In the output summary of the model above, there are a number of features you should pay attention to:
Coefficient Estimates - these are the \(\beta_0\) (intercept) and \(\beta_1\) (slope) parameter estimates from Equation 1. You will notice that at \(\beta_0 = 1.2\) and \(\beta_1 = 0.64\) they are pretty close (not awful!) to the estimates of 4 and 0.5 that we read from the graph earlier, but more precise.
Coefficient Standard Errors - these represent the average amount the coefficient varies from the average value of the dependent variable (its standard deviation). So, for a 1% increase in percent with no qualifications, while the model says we might expect percent of smokers to rise by 0.6%, this might vary, on average, by about 0.08%. As a rule of thumb, we are looking for a lower value in the standard error relative to the size of the coefficient.
Note that is the coefficient represents a one unit change, here it is %, as the variable is % unauthorized absence in school So one unit is a 1% change…
Coefficient t-value - this is the value of the coefficient divided by the standard error and so can be thought of as a kind of standardised coefficient value. The larger (either positive or negative) the value the greater the relative effect that particular independent variable is having on the dependent variable (this is perhaps more useful when we have several independent variables in the model) .
Coefficient p-value - Pr(>|t|) - the p-value is a measure of significance. There is lots of debate about p-values which I won’t go into here, but essentially it refers to the probability of getting a coefficient as large as the one observed in a set of random data. p-values can be thought of as percentages, so if we have a p-value of 0.5, then there is a 5% chance that our coefficient could have occurred in some random data, or put another way, a 95% chance that out coefficient could have only occurred in our data.
As a rule of thumb, the smaller the p-value, the more significant that variable is in the story and the smaller the chance that the relationship being observed is just random. Generally, statisticians use 5% or 0.05 as the acceptable cut-off for statistical significance - anything greater than that we should be a little sceptical about.
In r the codes ***, **, **, . are used to indicate significance. We generally want at least a single * next to our coefficient for it to be worth considering.
R-Squared - This can be thought of as an indication of how good your model is - a measure of ‘goodness-of-fit’ (of which there are a number of others). \(r^2\) is quite an intuitive measure of fit as it ranges between 0 and 1 and can be thought of as the % of variation in the dependent variable (in our case percentage of smokers) explained by variation in the independent variable(s). In our example, an \(r^2\) value of 0.47 indicates that around 47% of the variation in percentage of smokers can be explained by variation in percentage with no qualifications. In other words, this is quite a good model. The \(r^2\) value will increase as more independent explanatory variables are added into the model, so where this might be an issue, the adjusted r-squared value can be used to account for this affect.
4.3.2 Assumptions underpinning linear regression
4.3.2.1 Assumption 1 - there is a linear relationship between the dependent and independent variables
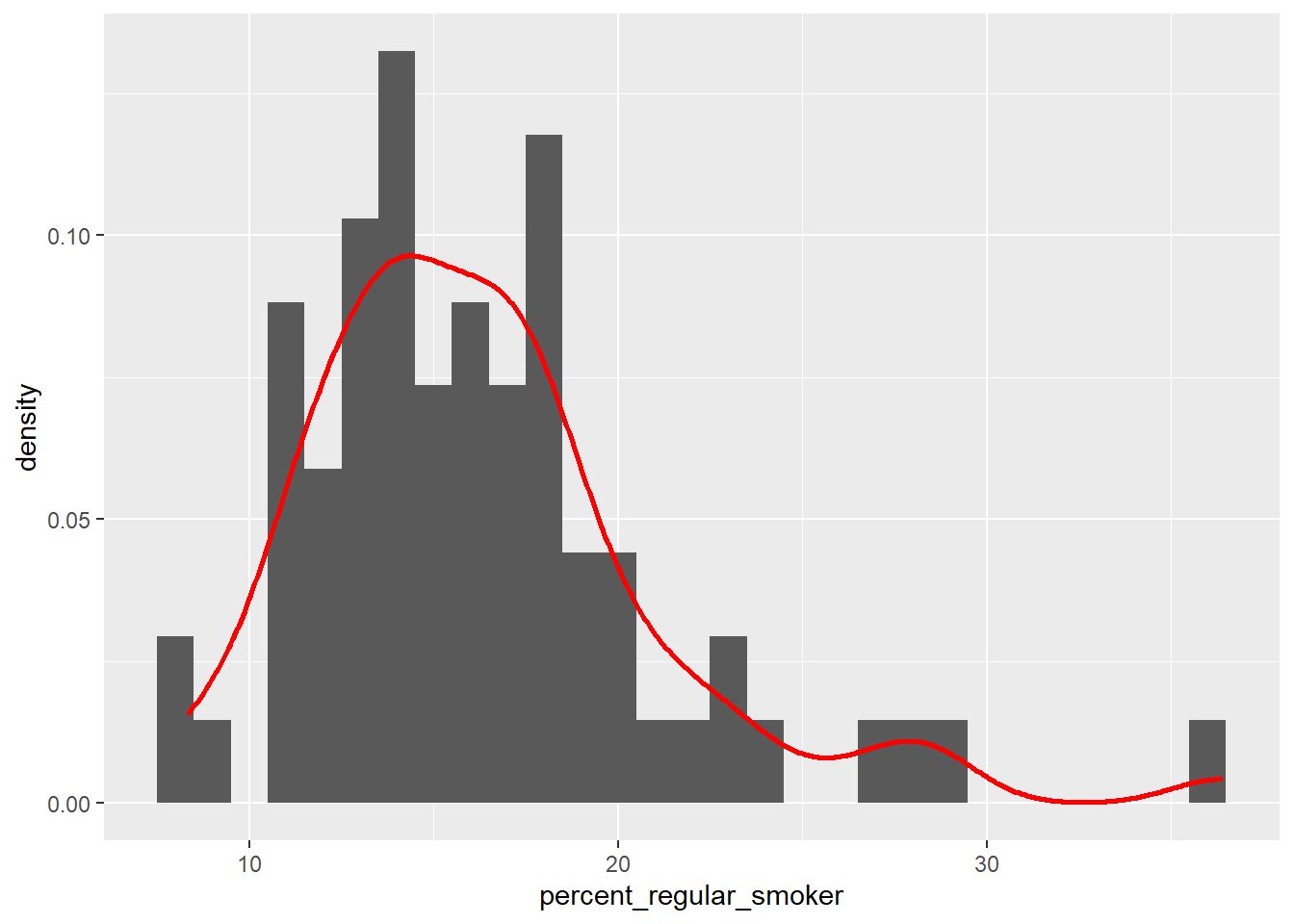
The best way to test for this assumption is to plot a scatter plot similar to the one created earlier. It may not always be practical to create a series of scatter plots, so one quick way to check that a linear relationship is probable is to look at the frequency distributions of the variables. If they are normally distributed, then there is a good chance that if the two variables are in some way correlated, this will be a linear relationship.
For example, look at the frequency distributions of our two variables earlier:
#let's check the distribution of these variables firstggplot(census_authorities_data_norm,aes(x=percent_regular_smoker)) +geom_histogram(aes(y =after_stat(density)),binwidth =1) +geom_density(colour="red", size=1, adjust=1)
Here, adding after_stat(density) means that the histogram is a density plot, this plots the chance that any value in the data is equal to that value.
It is not a requirement of regression to have normally distributed variables, however if they aren’t the residuals may well be normally distributed, but could vary (meaning we have hetroscedasticity) which we discuss later on.
One way that we might be able to achieve a linear relationship between our two variables is to transform the non-normally distributed variable so that it is more normally distributed. For more information on this see transforming variables.
However you will be changing the relationship of your data - it won’t be linear anymore! This could improve your model but is at the expense of interpretation. Aside from log transformation which has the rules in the link above.
Typically if you do a power transformation you can keep the direction of the relationship (positive or negative) and the t-value will give an idea of the importance of the variable in the model - that’s about it!
4.3.2.2 Assumption 2 - the residuals in your model should be normally distributed
This assumption is easy to check. When we ran our model1 earlier, one of the outputs stored in our model 1 object is the residual value for each case (authority) in your dataset. We can access these values using augment() from broom which will add model output to the original data…
We can plot these as a histogram and see if there is a normal distribution:
library(broom)#save the residuals into your dataframemodel_data <- model1 %>%augment(., census_authorities_data_norm)#plot residualsmodel_data%>%dplyr::select(.resid)%>%pull()%>%qplot()+geom_histogram()
Examining the histogram above, i am happy this is rather normal although there is evidently an outlier in our data somewhere.
4.3.2.3 Assumption 3 - no multicolinearity in the independent variables
Now, the regression model we have be experimenting with so far is a simple bivariate (two variable) model. One of the nice things about regression modelling is while we can only easily visualise linear relationships in a two (or maximum 3) dimension scatter plot, mathematically, we can have as many dimensions / variables as we like.
As such, we could extend model 1 into a multiple regression model by adding some more explanatory variables that we think could affect the percentage of people smoking…
Call:
lm(formula = percent_regular_smoker ~ percent_no_qualification +
percent_home_owner + census_2018_total_personal_income_median_curp_15years_and_over,
data = census_authorities_data_norm)
Residuals:
Min 1Q Median 3Q Max
-7.9633 -1.6181 -0.4151 1.3204 12.1627
Coefficients:
Estimate
(Intercept) 1.762e+01
percent_no_qualification 7.757e-01
percent_home_owner -3.992e-01
census_2018_total_personal_income_median_curp_15years_and_over -3.922e-05
Std. Error
(Intercept) 5.089e+00
percent_no_qualification 9.198e-02
percent_home_owner 7.015e-02
census_2018_total_personal_income_median_curp_15years_and_over 9.961e-05
t value Pr(>|t|)
(Intercept) 3.463 0.000959
percent_no_qualification 8.433 5.57e-12
percent_home_owner -5.690 3.40e-07
census_2018_total_personal_income_median_curp_15years_and_over -0.394 0.695119
(Intercept) ***
percent_no_qualification ***
percent_home_owner ***
census_2018_total_personal_income_median_curp_15years_and_over
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.96 on 64 degrees of freedom
Multiple R-squared: 0.6564, Adjusted R-squared: 0.6403
F-statistic: 40.75 on 3 and 64 DF, p-value: 7.514e-15
Examining the output above, it is clear that including these variables into our model improves the fit from an \(r^2\) of around 47% to an \(r^2\) of 65%. However, income is not significant so we should consider removing it..
Call:
lm(formula = percent_regular_smoker ~ percent_no_qualification +
percent_home_owner, data = census_authorities_data_norm)
Residuals:
Min 1Q Median 3Q Max
-7.6020 -1.6175 -0.3927 1.2883 11.7795
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 16.02096 3.04321 5.264 1.70e-06 ***
percent_no_qualification 0.79755 0.07283 10.950 < 2e-16 ***
percent_home_owner -0.40092 0.06955 -5.764 2.45e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.941 on 65 degrees of freedom
Multiple R-squared: 0.6556, Adjusted R-squared: 0.645
F-statistic: 61.86 on 2 and 65 DF, p-value: 9.037e-16
Here we see the \(r^2\) is almost the same. But do our two explanatory variables satisfy the no-multicoliniarity assumption? If not and the variables are highly correlated, then we are effectively double counting the influence of these variables and overstating their explanatory power
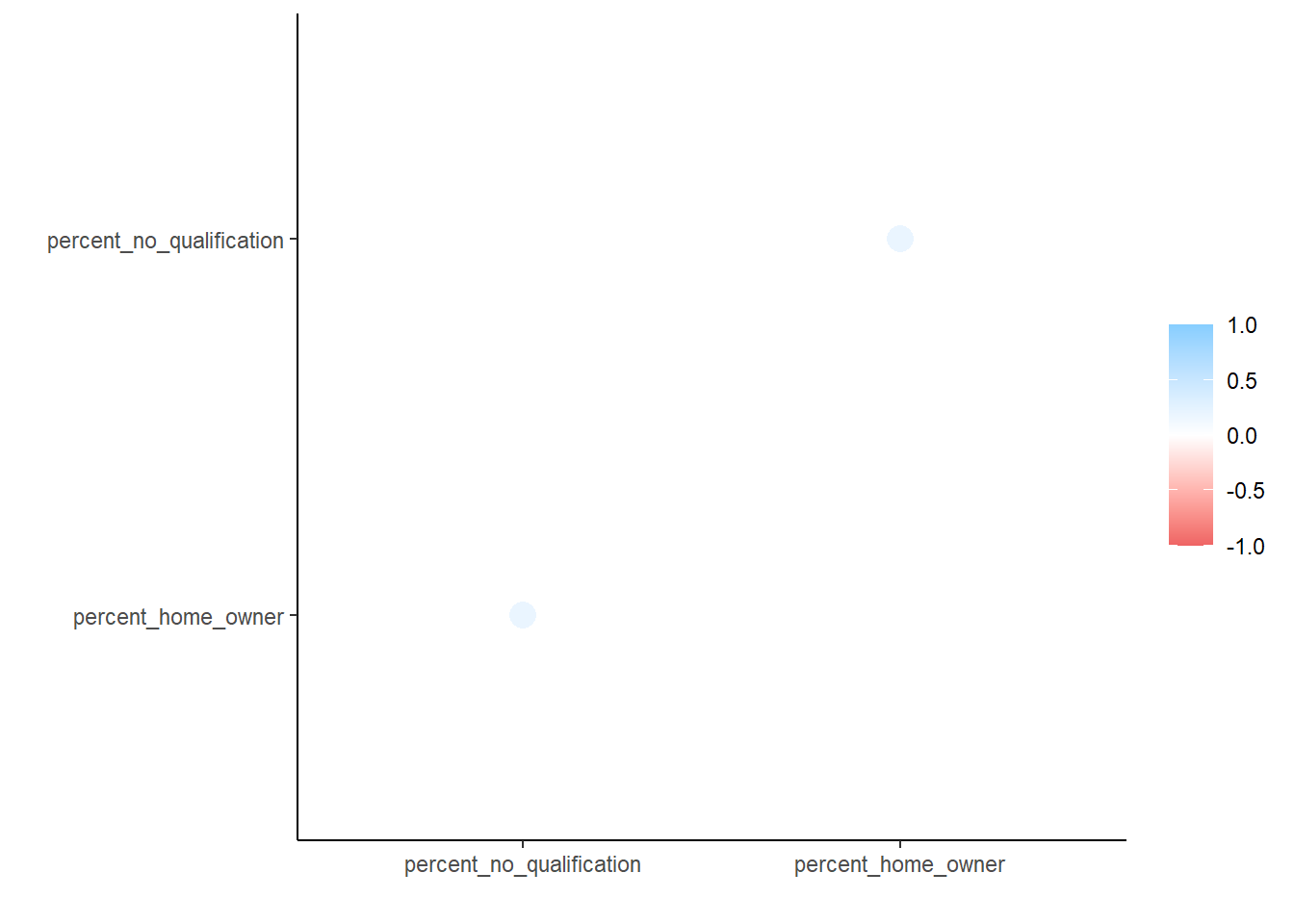
To check this, we can compute the product moment correlation coefficient between the variables, using the corrr() package, that’s part of tidymodels. In an ideal world, we would be looking for something less than a 0.8 correlation
library(corrr)correlation <- census_authorities_data_norm %>% dplyr::select(percent_no_qualification, percent_home_owner)%>%correlate()#visualise the correlation matrixrplot(correlation)
correlation
# A tibble: 2 × 3
term percent_no_qualification percent_home_owner
<chr> <dbl> <dbl>
1 percent_no_qualification NA 0.360
2 percent_home_owner 0.360 NA
Another way that we can check for Multicolinearity is to examine the VIF for the model. If we have VIF values for any variable exceeding 10, then we may need to worry and perhaps remove that variable from the analysis:
Homoscedasticity means that the errors/residuals in the model exhibit constant / homogeneous variance, if they don’t, then we would say that there is hetroscedasticity present. Why does this matter? Andy Field does a much better job of explaining this in discovering statistics — but essentially, if your errors do not have constant variance, then your parameter estimates could be wrong, as could the estimates of their significance.
The best way to check for homo/hetroscedasticity is to plot the residuals in the model against the predicted values. We are looking for a cloud of points with no apparent patterning to them.
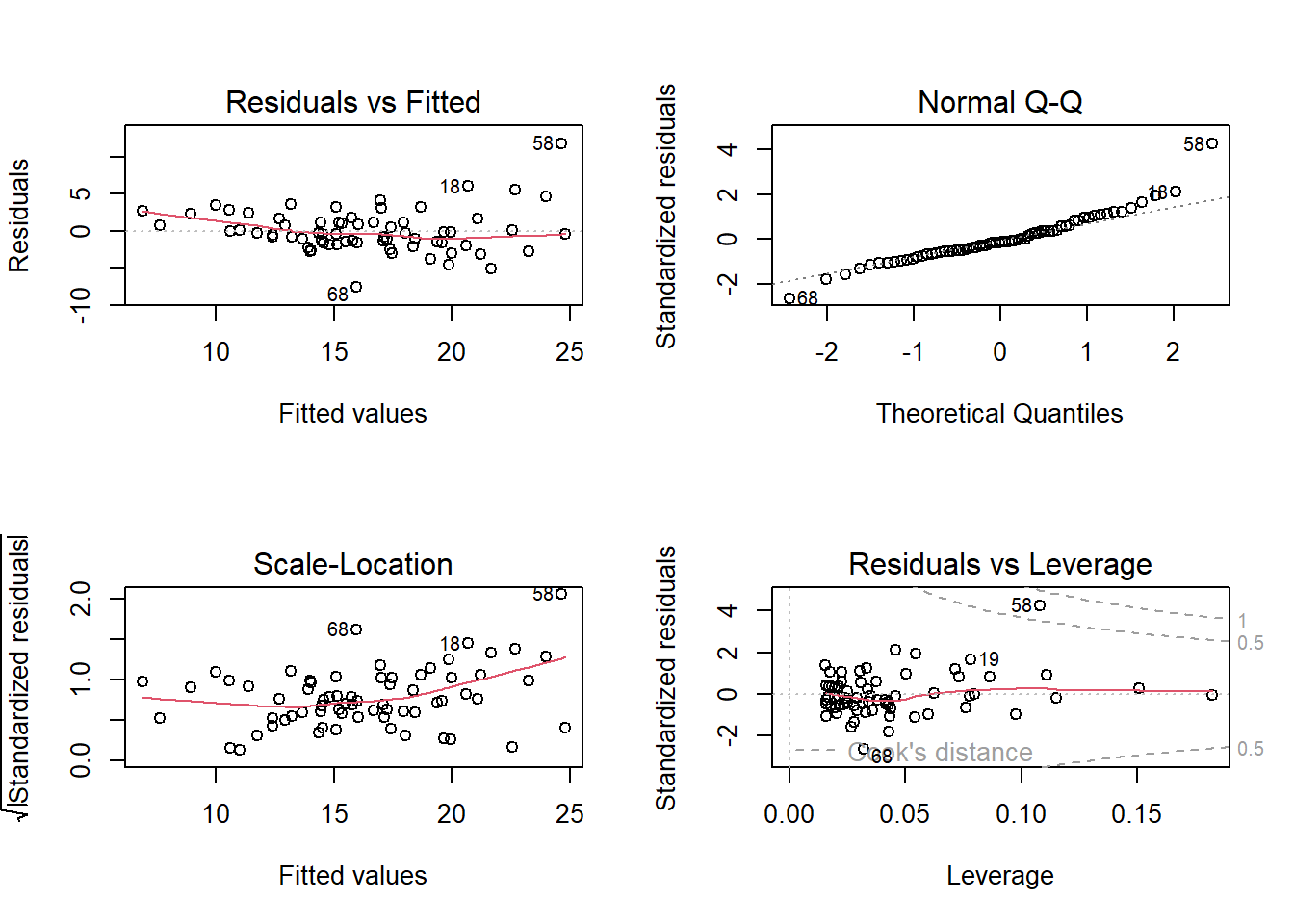
#print some model diagnositcs. par(mfrow=c(2,2)) #plot to 2 by 2 arrayplot(model2)
In the series of plots above, the first plot (residuals vs fitted), we would hope to find a random cloud of points with a straight horizontal red line. Looking at the plot, the curved red line would suggest some hetroscedasticity, but the cloud looks quite random. Similarly we are looking for a random cloud of points with no apparent patterning or shape in the third plot of standardised residuals vs fitted values. Here, the cloud of points also looks fairly random, with perhaps some shaping indicated by the red line.
Residuals vs Fitted: a flat and horizontal line. This is looking at the linear relationship assumption between our variables
Normal Q-Q: all points falling on the line. This checks if the residuals (observed minus predicted) are normally distributed
Scale vs Location: flat and horizontal line, with randomly spaced points. This is the homoscedasticity (errors/residuals in the model exhibit constant / homogeneous variance). Are the residuals (also called errors) spread equally along all of the data.
Residuals vs Leverage - Identifies outliers (or influential observations), the three largest outliers are identified with values in the plot.
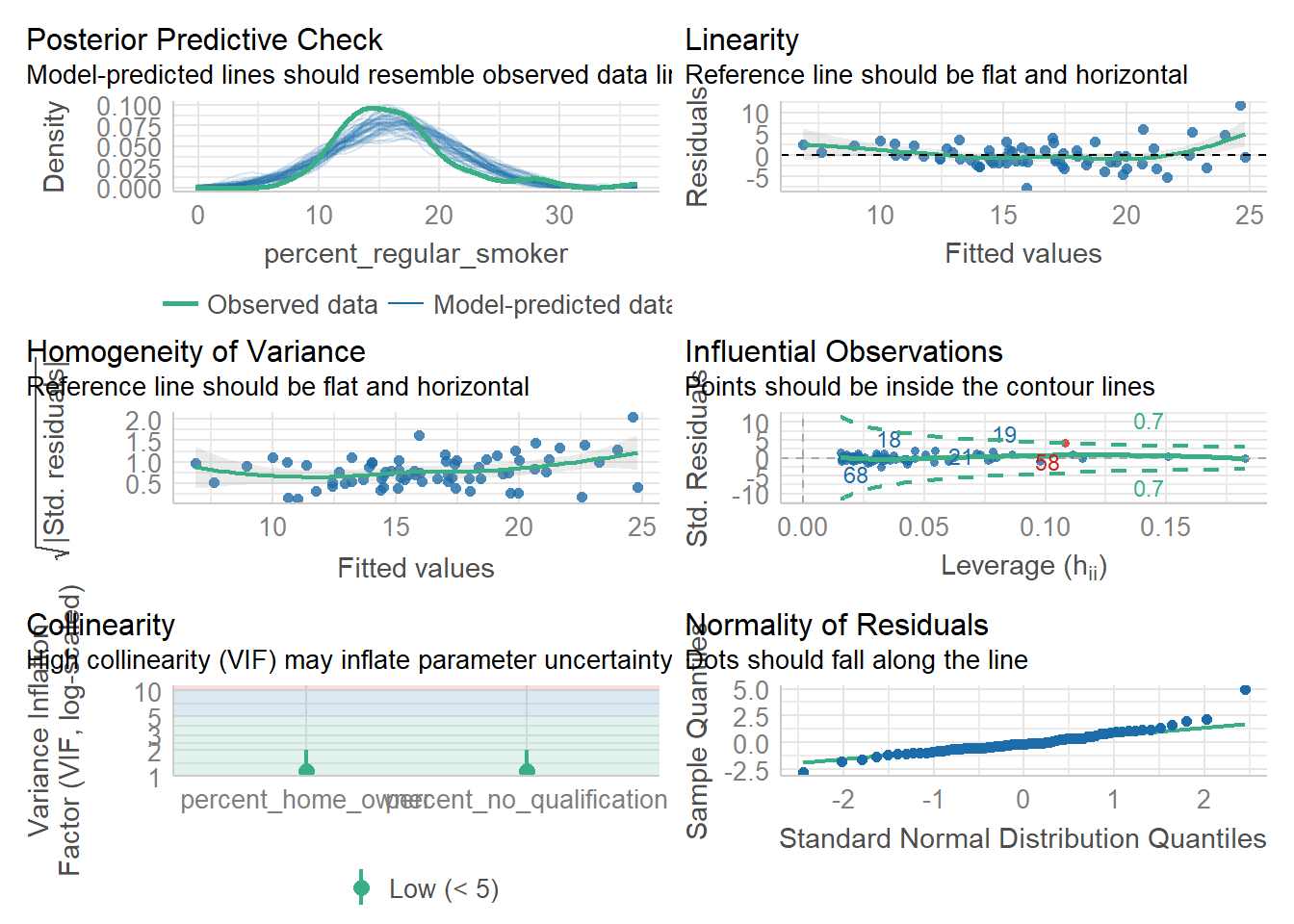
There is an easier way to produce this plot using check_model() from the performance package, that even includes what you are looking for…note that the Posterior predictive check is the comparison between the fitted model and the observed data.
This assumption simply states that the residual values (errors) in your model must not be correlated in any way. If they are, then they exhibit autocorrelation which suggests that something might be going on in the background that we have not sufficiently accounted for in our model.
4.3.2.5.1 Standard autocorrelation
If you are running a regression model on data that do not have explicit space or time dimensions, then the standard test for autocorrelation would be the Durbin-Watson test.
This tests whether residuals are correlated and produces a summary statistic that ranges between 0 and 4, with 2 signifying no autocorrelation. A value greater than 2 suggesting negative autocorrelation and and value of less than 2 indicating positive autocorrelation.
In his excellent text book, Andy Field suggests that you should be concerned with Durbin-Watson test statistics <1 or >3. So let’s see:
Call:
lm(formula = percent_regular_smoker ~ percent_no_qualification +
percent_home_owner + census_2018_total_personal_income_median_curp_15years_and_over,
data = census_authorities_data_norm_filter)
Residuals:
Min 1Q Median 3Q Max
-3.6984 -1.5153 -0.4655 1.2802 5.3085
Coefficients:
Estimate
(Intercept) 2.796e+01
percent_no_qualification 5.152e-01
percent_home_owner -3.051e-01
census_2018_total_personal_income_median_curp_15years_and_over -3.295e-04
Std. Error
(Intercept) 3.939e+00
percent_no_qualification 7.357e-02
percent_home_owner 5.305e-02
census_2018_total_personal_income_median_curp_15years_and_over 8.034e-05
t value Pr(>|t|)
(Intercept) 7.098 1.45e-09
percent_no_qualification 7.002 2.13e-09
percent_home_owner -5.752 2.92e-07
census_2018_total_personal_income_median_curp_15years_and_over -4.101 0.000122
(Intercept) ***
percent_no_qualification ***
percent_home_owner ***
census_2018_total_personal_income_median_curp_15years_and_over ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.118 on 62 degrees of freedom
Multiple R-squared: 0.7607, Adjusted R-squared: 0.7491
F-statistic: 65.68 on 3 and 62 DF, p-value: < 2.2e-16
We see that the \(r^2\) has jumped to 76%…now Durbin Watson test and map again.
dw <-durbinWatsonTest(model3)tidy(dw)
# A tibble: 1 × 5
statistic p.value autocorrelation method alternative
<dbl> <dbl> <dbl> <chr> <chr>
1 1.27 0.00400 0.345 Durbin-Watson Test two.sided
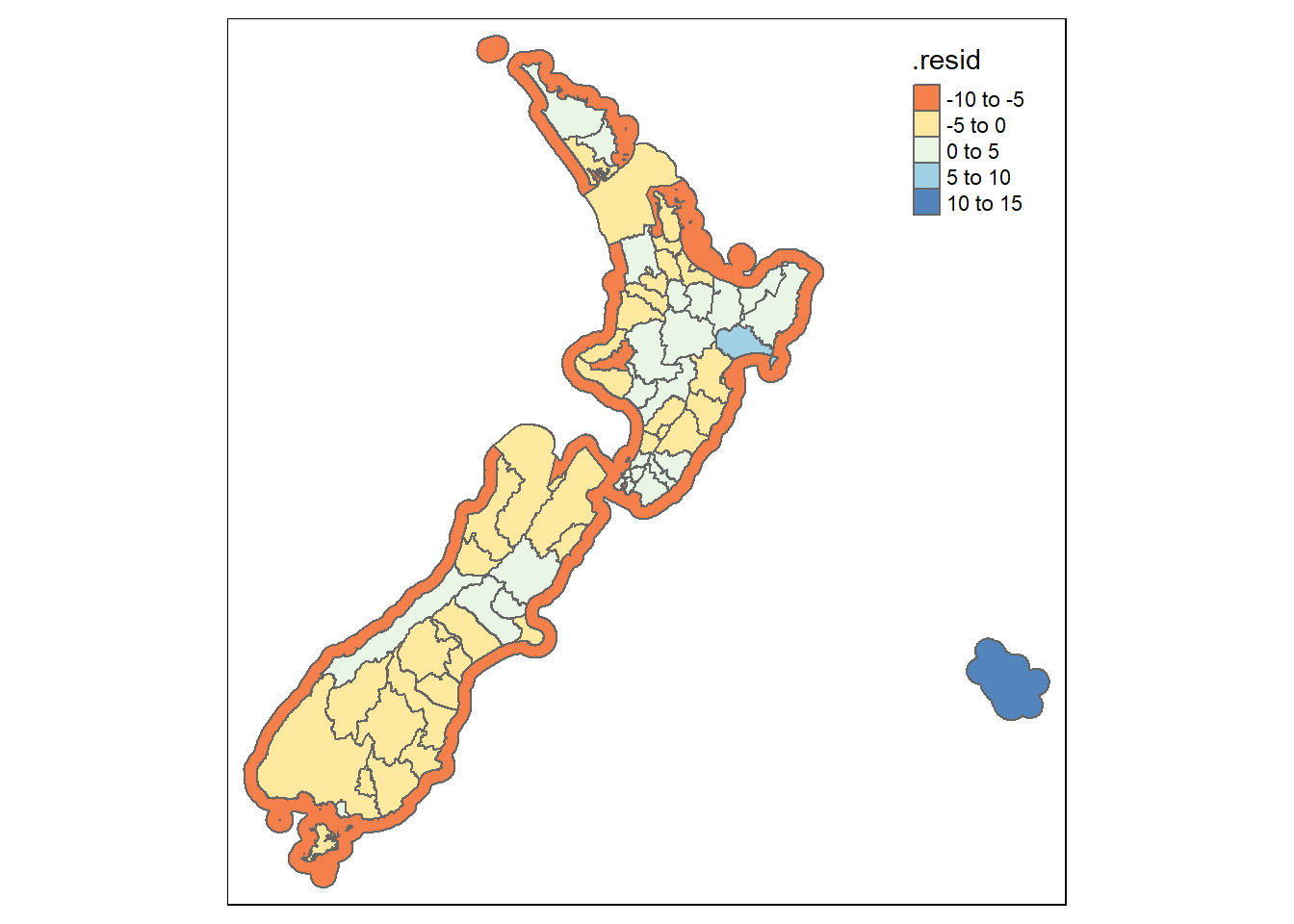
#and for future use, write the residuals outmodel3_residuals <- model3 %>%augment(., census_authorities_data_norm_filter)ta_model3_data<- ta%>%clean_names(.)%>%left_join(., model3_residuals,by=c("ta2018_v1"="area_code"))tm_shape(ta_model3_data) +tm_polygons(".resid",palette ="RdYlBu")
This suggests that there could well be some spatial autocorrelation biasing our model, but can we test for spatial autocorrelation more systematically?
Yes - and some of you will remember this from the practical two weeks ago. We can calculate a number of different statistics to check for spatial autocorrelation - the most common of these being Moran’s I.
library(spdep)#Now we need to generate a spatial weights matrix #We'll start with a simple binary matrix of queen's case neighboursta_nb <- ta_model3_data %>%poly2nb(., queen=T)#or nearest neighboursta_knn <-coordsW %>%knearneigh(., k=4)ta_knn_nb <- ta_knn %>%knn2nb()#plot themplot(ta_nb, st_geometry(coordsW), col="red")
#create a spatial weights matrix object from these weightsta_queens_weight <- ta_nb %>%nb2listw(., style="W")ta_knn_4_weight <- ta_knn_nb %>%nb2listw(., style="W")
The style argument means the style of the output — B is binary encoding listing them as neighbours or not, W row standardised that we saw yesterday.
Now run a Moran’s I test on the residuals, first using queens neighbours
# A tibble: 1 × 7
estimate1 estimate2 estimate3 statistic p.value method alter…¹
<dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 0.342 -0.0154 0.00818 3.95 0.0000387 Moran I test under … greater
# … with abbreviated variable name ¹alternative
nearest_neighbour
# A tibble: 1 × 7
estimate1 estimate2 estimate3 statistic p.value method alter…¹
<dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 0.334 -0.0154 0.00622 4.43 0.00000474 Moran I test under… greater
# … with abbreviated variable name ¹alternative
Observing the Moran’s I statistic for both Queen’s case neighbours and k-nearest neighbours of 4, we can see that the Moran’s I statistic is somewhere between 0.34 and 0.33. Remembering that Moran’s I ranges from between -1 and +1 (0 indicating no spatial autocorrelation) we can conclude that there is some weak to moderate spatial autocorrelation in our residuals.
This means that despite passing most of the assumptions of linear regression, we could have a situation here where the presence of some spatial autocorrelation could be leading to biased estimates of our parameters and significance values.
4.4 Spatial regression models
4.4.1 The spatial lag (lagged dependent variable) model
Rrunning a Moran’s I test on the residuals from the model suggested that there might be some spatial autocorreation occurring suggesting that places where the model over-predicted the percent of people smoking (those shown in blue in the map above with negative residuals) and under-predicted (those shown in red/orange) occasionally were near to each other.
Ward and Gleditsch (2008) describe this situation (where the value of our \(y\) dependent variable - percent people who smoke - may be influenced by neighbouring values) and suggest the way to deal with it is to incorporate a spatially-lagged version of this variable amongst the independent variables on the right-hand side of the equation. In this case, Equation 1 would be updated to look like this:
In this equation, \(w\) is the spatial weights matrix you generated and \(w_i\) is vector of all neighbouring areas (in our case, Wards) for any Ward \(y_i\). If using binary this will be a sum (e.g. the value of \(y\) plotted against the sum of \(y\) of the neighbouring wards). This may be explained as a weighted sum as the non-neighbours will be removed, the weight being the neighbours If this is row standardised it will be a weighted average of the neighbouring \(y\) values. Typically we use a row standardised matrix.
In this model, a positive value for the \(\rho w_i.y_i\) parameter would indicate that the average value for the percent smoking is expected to be higher if, on average, neighbouring authorities also have a higher percentage of people who smoke.
\(\rho\) denotes (represents) the spatial lag
For more details on running a spatially lagged regression model and interpreting the outputs, see the chapter on spatially lagged models by Ward and Gleditsch (2008) available online here: https://methods.sagepub.com/book/spatial-regression-models/n2.xml
4.4.1.1 Queen’s case lag
Now run a spatially-lagged regression model with a queen’s case weights matrix
library(spatialreg)slag_dv_model2_queen <-lagsarlm(percent_regular_smoker ~ percent_no_qualification + percent_home_owner + census_2018_total_personal_income_median_curp_15years_and_over,data = ta_model3_data, nb2listw(ta_nb, style="C"), method ="eigen")#what do the outputs show?tidy(slag_dv_model2_queen)
Running the spatially-lagged model with a Queen’s case spatial weights matrix reveals that in this example, there is an insignificant and small effect associated with the spatially lagged dependent variable. However, a different conception of neighbours we might get a different outcome….
Here:
Rho is our spatial lag (0.0232) that measures the variable in the surrounding spatial areas as defined by the spatial weight matrix. We use this as an extra explanatory variable to account for clustering (identified by Moran’s I). If significant it means that the percent of smokers in a unit vary based on the percent of smokers in the neighboring units. If it is positive it means as the percent of smokers increase in the surrounding units so does our central value
Log likelihood shows how well the data fits the model (like the AIC, which we cover later), the higher the value the better the models fits the data.
Likelihood ratio (LR) test shows if the addition of the lag is an improvement (from linear regression) and if that’s significant. This code would give the same output…
Lagrange Multiplier (LM) is a test for the absence of spatial autocorrelation in the lag model residuals. If significant then you can reject the Null (no spatial autocorrelation) and accept the alternative (is spatial autocorrelcation)
Wald test (often not used in interpretation of lag models), it tests if the new parameters (the lag) should be included it in the model…if significant then the new variable improves the model fit and needs to be included. This is similar to the LR test and i’ve not seen a situation where one is significant and the other not. Probably why it’s not used!
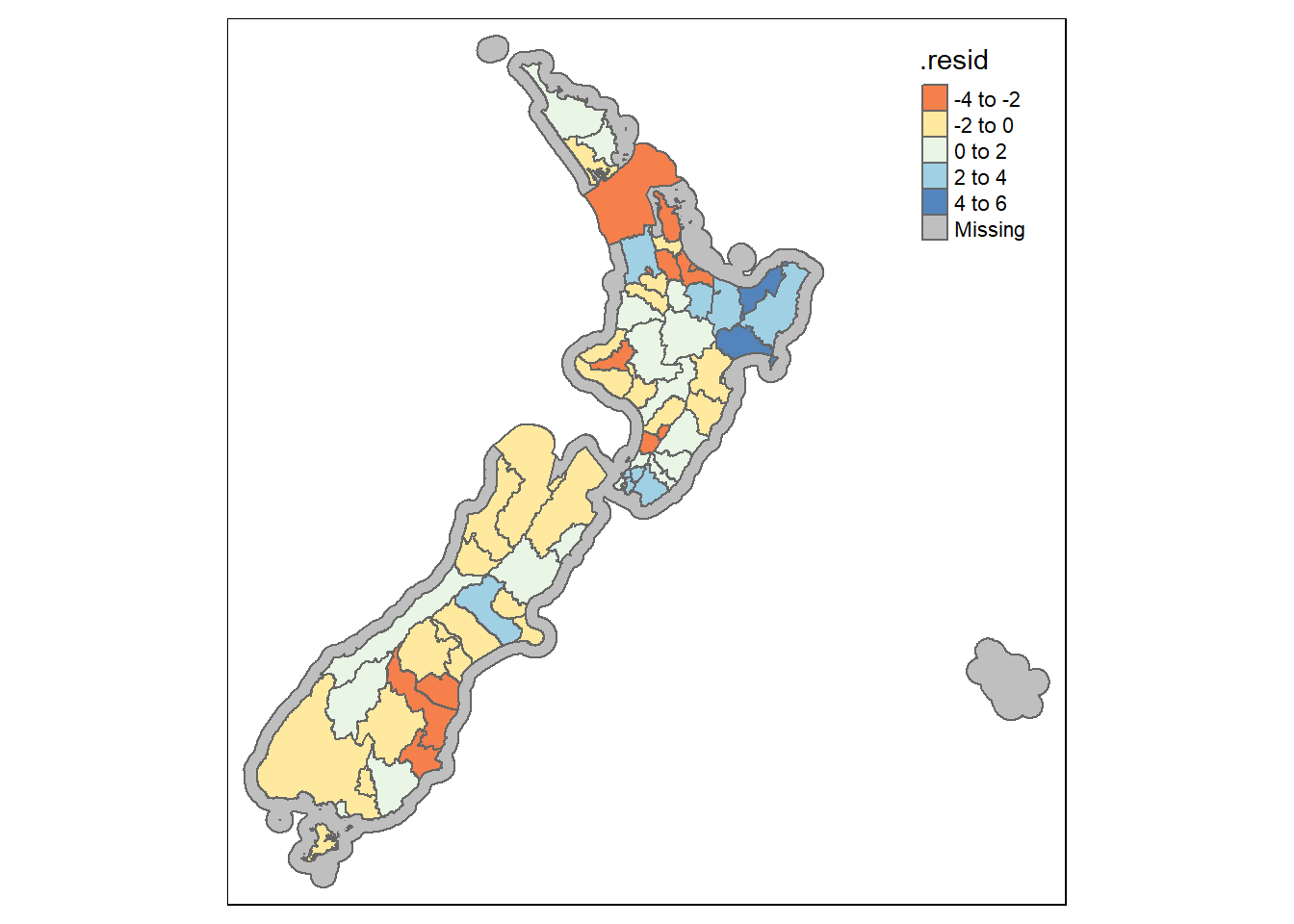
In this case we have spatial autocorrelation in the residuals of the model, but the model is not an improvement on OLS — this can also be confirmed with the AIC score (we cover that later) but the lower it is the better. Here it is 293, in OLS (model 3) it was 292. The Log likelihood for model 3 (OLS) was -141, here it is -140.
4.4.1.1.1 Lag impacts
Warning according to Solymosi and Medina (2022) you must not not compare the coefficients of this to regular OLS…Why ?
Well in OLS recall we can use the coefficients to say…a 1 unit change in the independent variable means a drop or rise in the dependent (for a 1% increase in percent with no qualifications the percent of smokers rises by 0.64 percent). BUT here the model is not consistent as the observations will change based on the weight matrix neighbours selected which might vary (almost certainly in a distance based matrix). This means we have a direct effect (standard OLS) and then an indirect effect in the model (impact of the spatial lag).
We can compute these direct and indirect effects using code from Solymosi and Medina (2022) and the spatialreg package. Here the impacts() function calculates the impact of the spatial lag. We can fit this to our entire spatial weights….
library(spdep)# weight list is just the code from the lagsarlmweight_list<-nb2listw(ta_knn_nb, style="C")imp <-impacts(slag_dv_model2_queen, listw=weight_list)imp
Now it is appropriate to compare these coefficients to the OLS outputs…however if you have a very large matrix this might not work, instead a sparse matrix that uses approximation methods (see Solymosi and Medina (2022) and within that resource, Lesage and Pace 2009). This is beyond the scope of the content here, but essentially this makes the method faster on larger data…but only row standardised is permitted here…
4.4.2 The spatial error model
Another way of coneptualising spatial dependence in regression models is not through values of the dependent variable in some areas affecting those in neighbouring areas (as they do in the spatial lag model), but in treating the spatial autocorrelation in the residuals as something that we need to deal with, perhaps reflecting some spatial autocorrelation amongst unobserved independent variables or some other mis-specification of the model.
Ward and Gleditsch (2008) characterise this model as seeing spatial autocorrelation as a nuisance rather than being particularly informative, however it can still be handled within the model, albeit slightly differently.
\(\xi_i\) is the spatial component of the error terms…in other words the residuals of the values in surrounding spatial units based on the weight matrix. The same rules apply as the lag (e.g. binary = sum, row standardisied = weighted average).
\(\lambda\) is a measure of correlation between neighbouring residuals.. “it indicates the extent to which the spatial component of the errors \(\xi_i\) are correlated with one another for nearby observations” as per the weight matrix, Ward and Gleditsch (2008). If there is no correlation between the then this defaults to normal OLS regression
For more detail on the spatial error model, see Ward and Gleditsch (2008) - https://methods.sagepub.com/Book/spatial-regression-models/n3.xml
We can run a spatial error model on the same data below:
Comparing the results of the spatial error model with the spatially lagged model and the original OLS model, the suggestion here is that the spatially correlated errors in residuals lead to over/under estimations of the coefficients.
Note, here we can compare to OLS as there is no spatial lag.
The \(\lambda\) parameter in the spatial error model is larger than the standard error and is significant, but the \(\rho\) parameter is not larger than the standard error and is not significant.
So we can conclude that spatial dependence might be borne in mind when interpreting the results of this regression model. This suggests to us that the smoking is not influenced by neighbouring polygons (or smokers) but the errors between the neighours are related and we may have some mis-specification of the model - e.g. a missing variable.
4.4.3 Key advice
The lag model accounts for situations where the value of the dependent variable in one area might be associated with or influenced by the values of that variable in neighbouring zones (however we choose to define neighbouring in our spatial weights matrix). With our example, smoking in one neighbourhood might be related to smoking in another. You may be able to think of other examples where similar associations may occur. You might run a lag model if you identify spatial autocorrelation in the dependent variable (closer spatial units have similar values) with Moran’s I.
The error model deals with spatial autocorrelation (closer spatial units have similar values) of the residuals (vertical distance between your point and line of model – errors – over-predictions or under-predictions) again, potentially revealed though a Moran’s I analysis. The error model is not assuming that neighbouring independent variables are influencing the dependent variable but rather the assumption is of an issue with the specification of the model or the data used (e.g. clustered errors are due to some un-observed clustered variables not included in the model). For example, smoking prevelance may be similar in bordering neighbourhoods because residents in these neighbouring places come from similar socio-economic backgrounds and this was not included as an independent variable in the original model. There is no spatial process (no cross authority interaction) just a cluster of an un-accounted for but influential variable.
4.5 GWR
Rather than spatial autocorrelation causing problems with our model, it might be that a “global” regression model does not capture the full story. In some parts of our study area, the relationships between the dependent and independent variable may not exhibit the same slope coefficient.
If this occurs, then we have ‘non-stationarity’ - this is when the global model does not represent the relationships between variables that might vary locally.
4.5.1 Bandwidth
This part of the practical will only skirt the edges of GWR, for much more detail you should visit the GWR website which is produced and maintained by Prof Chris Brunsdon and Dr Martin Charlton who originally developed the technique - http://gwr.nuim.ie/
Setting adapt=T here means to automatically find the proportion of observations for the weighting using k nearest neighbours (an adaptive bandwidth), False would mean a global bandwidth and that would be in meters (as our data is projected).
Occasionally data can come with longitude and latitude as columns (e.g. WGS84) and we can use this straight in the function to save making centroids, calculating the coordinates and then joining - the argument for this is longlat=TRUE and then the columns selected in the coords argument e.g. coords=cbind(long, lat). The distance result will then be in KM.
The optimal bandwidth is about 0.106 meaning 10.6% of all the total spatial units should be used for the local regression based on k-nearest neighbours. Which is about 7 of the 66 territorial authorities.
This approach uses cross validation to search for the optimal bandwidth, it compares different bandwidths to minimise model residuals — this is why we specify the regression model within gwr.sel(). It does this with a Gaussian weighting scheme (which is the default) - meaning that near points have greater influence in the regression and the influence decreases with distance - there are variations of this, but Gaussian is a fine to use in most applications. To change this we would set the argument gweight = gwr.Gauss in the gwr.sel() function — gwr.bisquare() is the other option. We don’t go into cross validation in this module.
However we could set either the number of neighbours considered or the distance within which to considered points ourselves, manually, in the gwr() function below.
To set the number of other neighbours considered simply change the adapt argument to the value you want - it must be the number of neighbours divided by the total (e.g. to consider 20 neighbours it would be 20/66 and you’d use the value of 0.30)
The set the bandwidth, remove the adapt argument and replace it with bandwidth and set it, in this case, in meters.
To conclude, we can:
set the bandwidth in gwr.sel() automatically using:
the number of neighbors
a distance threshold
Or, we can set it manually in gwr() using:
a number of neighbors
a distance threshold
Tip
BUT a problem with setting a fixed bandwidth is we assume that all variables have the same relationship across the same space (using the same number of neighbours or distance)…(such as rate_of_job_seekers_allowance_jsa_claimants_2015 and percent_with_level_4_qualifications_and_above_2011). We can let these bandwidths vary as some relationships will operate on different spatial scales…this is called Multiscale GWR and Lex Comber recently said that all GWR should be Multisacle (oops!). We have already covered a lot here so i won’t go into it. If you are interested Lex has a good tutorial on Multiscale GWR
4.5.2 Model
#run the gwr modelgwr_model =gwr(percent_regular_smoker ~ percent_no_qualification + percent_home_owner + census_2018_total_personal_income_median_curp_15years_and_over,data = ta_model3_data_gwr, coords=cbind(ta_model3_data_gwr$X, ta_model3_data_gwr$Y), adapt=gwrbandwidth,#matrix outputhatmatrix=TRUE,#standard errorse.fit=TRUE)#print the results of the modelgwr_model
Call:
gwr(formula = percent_regular_smoker ~ percent_no_qualification +
percent_home_owner + census_2018_total_personal_income_median_curp_15years_and_over,
data = ta_model3_data_gwr, coords = cbind(ta_model3_data_gwr$X,
ta_model3_data_gwr$Y), adapt = gwrbandwidth, hatmatrix = TRUE,
se.fit = TRUE)
Kernel function: gwr.Gauss
Adaptive quantile: 0.1060531 (about 6 of 66 data points)
Summary of GWR coefficient estimates at data points:
Min.
X.Intercept. 3.3703e+00
percent_no_qualification 4.1815e-01
percent_home_owner -4.4357e-01
census_2018_total_personal_income_median_curp_15years_and_over -9.2994e-04
1st Qu.
X.Intercept. 1.2399e+01
percent_no_qualification 4.8399e-01
percent_home_owner -3.1838e-01
census_2018_total_personal_income_median_curp_15years_and_over -5.2518e-04
Median
X.Intercept. 1.7101e+01
percent_no_qualification 5.2129e-01
percent_home_owner -2.4756e-01
census_2018_total_personal_income_median_curp_15years_and_over -9.6083e-05
3rd Qu.
X.Intercept. 3.4618e+01
percent_no_qualification 5.8085e-01
percent_home_owner -1.8668e-01
census_2018_total_personal_income_median_curp_15years_and_over -2.1233e-05
Max.
X.Intercept. 4.8631e+01
percent_no_qualification 6.9995e-01
percent_home_owner -1.6115e-01
census_2018_total_personal_income_median_curp_15years_and_over 1.9089e-04
Global
X.Intercept. 27.9622
percent_no_qualification 0.5152
percent_home_owner -0.3051
census_2018_total_personal_income_median_curp_15years_and_over -0.0003
Number of data points: 66
Effective number of parameters (residual: 2traceS - traceS'S): 25.09782
Effective degrees of freedom (residual: 2traceS - traceS'S): 40.90218
Sigma (residual: 2traceS - traceS'S): 1.503921
Effective number of parameters (model: traceS): 19.93781
Effective degrees of freedom (model: traceS): 46.06219
Sigma (model: traceS): 1.417184
Sigma (ML): 1.183931
AICc (GWR p. 61, eq 2.33; p. 96, eq. 4.21): 272.3116
AIC (GWR p. 96, eq. 4.22): 229.5246
Residual sum of squares: 92.51173
Quasi-global R2: 0.9204215
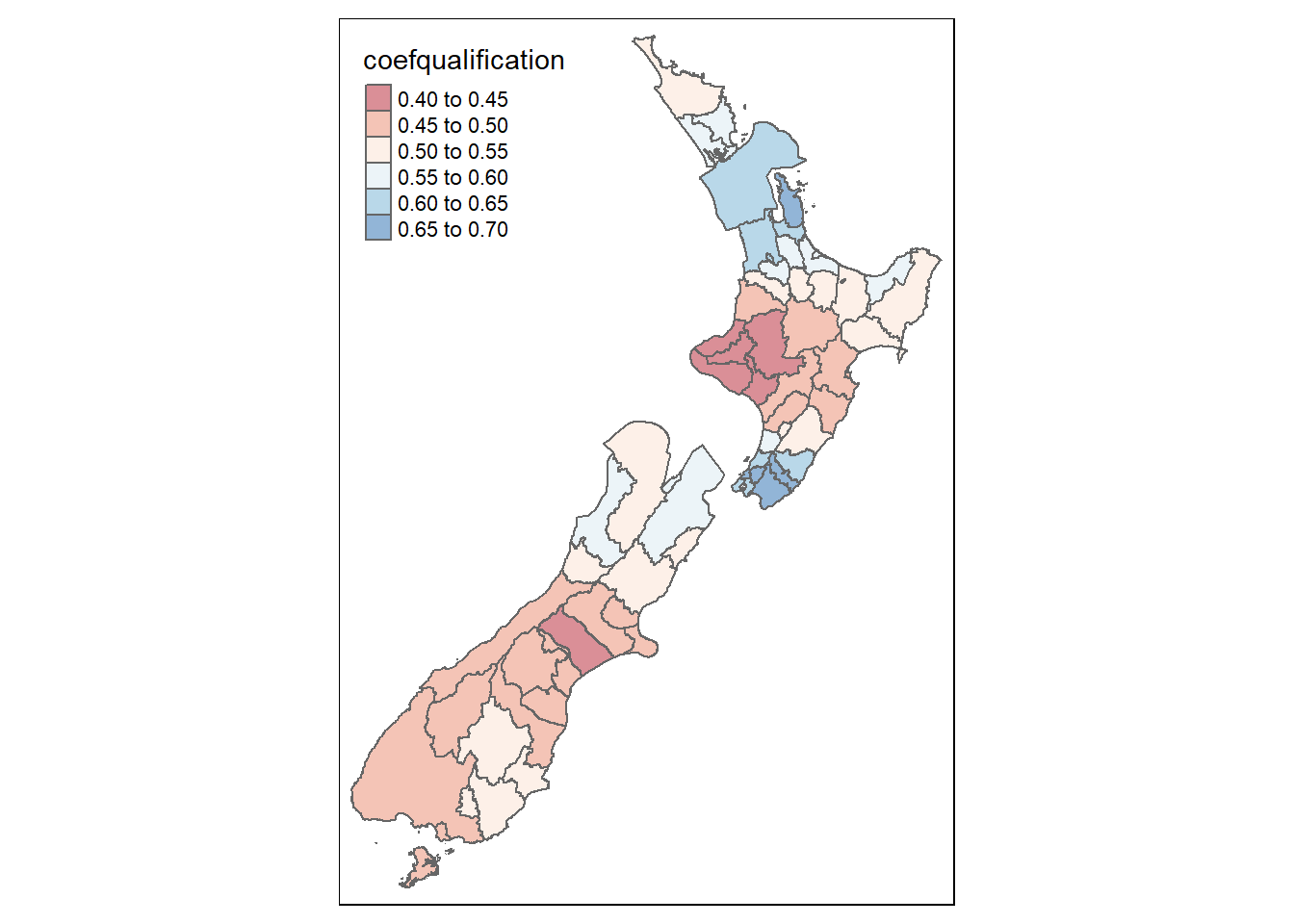
The output from the GWR model reveals how the coefficients vary across the 66 territorial authorities New Zealand. You will see how the global coefficients are exactly the same as the coefficients in the earlier lm model. In this particular model, if we take percent with no qualification, we can see that the coefficients range from a minimum value of 0.41 (1 unit change in percent with no qualification resulting in a rise in percent smoking of 0.41) to 0.69 (1 unit change in percent with no qualification resulting in a rise in percent smoking of 0.69).
You will notice that the R-Squared value (Quasi global R-squared) has improved - this is not uncommon for GWR models, but it doesn’t necessarily mean they are definitely better than global models. The small number of cases (spatial areas) under the kernel means that GW models have been criticised for lacking statistical robustness.
The best way to compare models is with the AIC (Akaike Information Criterion) or for smaller sample sizes the sample-size adjusted AICc, especially when you number of points is less than 40! Which it will be in GWR. The models must also be using the same data and be over the same study area!
AIC is calculated using the:
number of independent variables
maximum likelihood estimate of the model (how well the model reproduces the data).
The lower the value the better the better the model fit is, see scribbrif you want to know more here..although this is enough to get you through most situations.
Coefficient ranges can also be seen for the other variables and they suggest some interesting spatial patterning.
4.5.3 Map coefficients
To explore this we can plot the GWR coefficients for different variables. Firstly we can attach the coefficients to our original dataframe - this can be achieved simply as the coefficients for each territoiral authority appear in the same order in our spatial points dataframe as they do in the original dataframe.
Taking the first coefficient we see that this varies across the country. A possible trend to explore further might be the inclusion or distance to tobacco retailers - both Wellington and Auckland have some of the highest coefficients, meaning a 1 unit (percent) change in no qualification returns a higher rise in percent of people smoking.
4.5.4 Significance
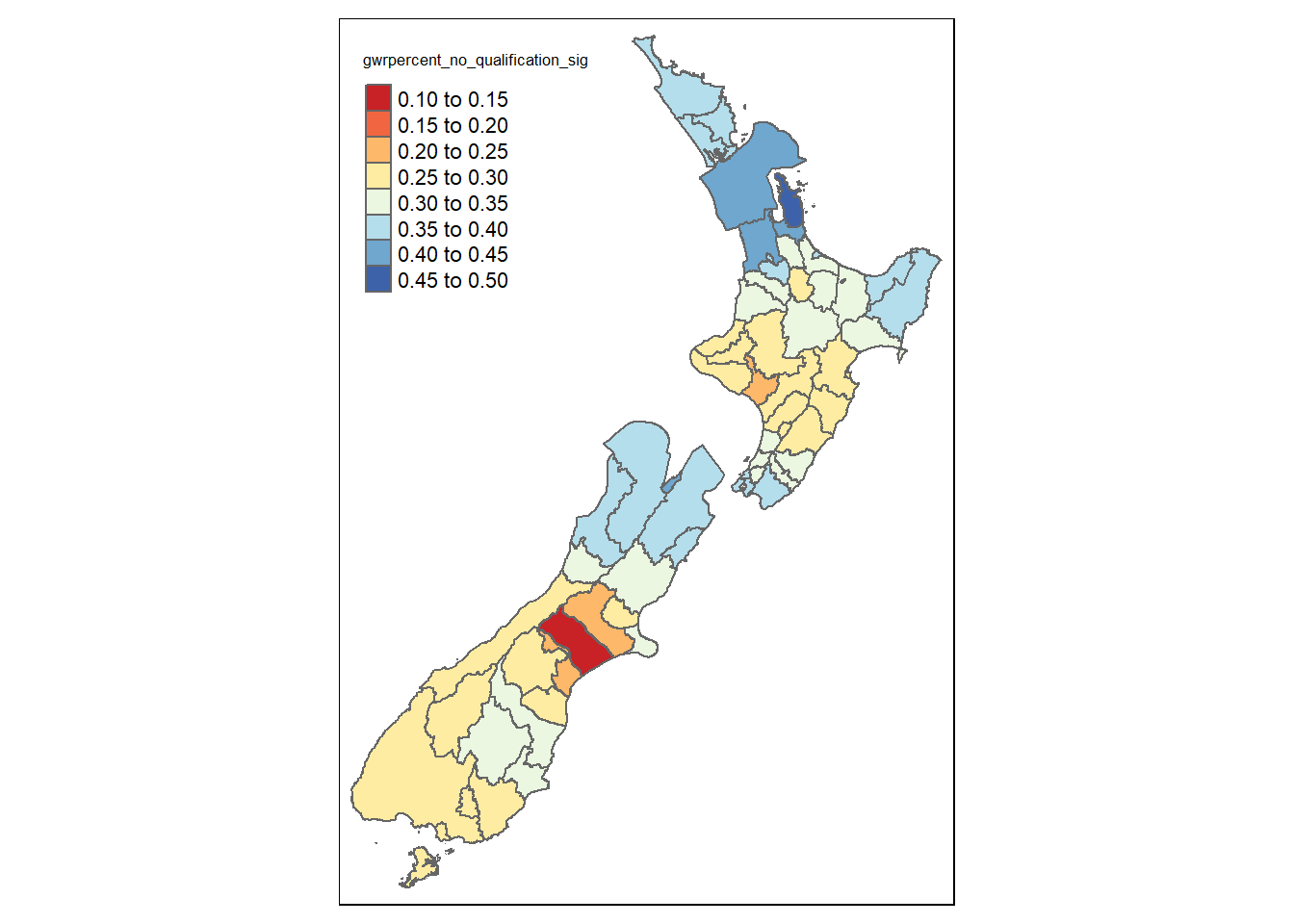
Of course, these results may not be statistically significant across the whole of New Zealand. Roughly speaking, if a coefficient estimate is more than 2 standard errors away from zero, then it is “statistically significant”.
Remember from earlier the standard error is “the average amount the coefficient varies from the average value of the dependent variable (its standard deviation). So, for 1% increase in percent with no qualifications, while the model says we might expect GSCE scores to drop by 0.6%, this might vary, on average, by about 0.08%. As a rule of thumb, we are looking for a lower value in the standard error relative to the size of the coefficient.”
To calculate standard errors, for each variable you can use a formula similar to this:
#run the significance test# abs gets the absolute vale - negative values are converted into positive valuesigTest =abs(gwr_model$SDF$percent_no_qualification)-2* gwr_model$SDF$percent_no_qualification_se#store significance resultsta_model3_data_gwr_results <- ta_model3_data_gwr_results %>%mutate(gwrpercent_no_qualification_sig = sigTest)
If this is greater than zero (i.e. the estimate is more than two standard errors away from zero), it is very unlikely that the true value is zero, i.e. it is statistically significant (at nearly the 95% confidence level)
This is a combination of two ideas:
95% of data in a normal distribution is within two standard deviations of the mean
Statistical significance in a regression is normally measured at the 95% level. If the p-value is less than 5% — 0.05 — then there’s a 95% probability that a coefficient as large as you are observing didn’t occur by chance
Combining these two means if…
the coefficient is large in relation to its standard error and
the p-value tells you if that largeness is statistically acceptable - at the 95% level (less than 5% — 0.05)
You can be confident that in your sample, nearly all of the time, that is a real and reliable coefficient value.
4.6 Including spatial features
I mentioned at the start we could also try and include some spatial features within our model - for example the density of shops that sell tobacco? In a sense this is similar to what is termed a spatially omitted covariate… typically this means that the nearer something is the more influence it might have on our model.
However, we could only really calculate distance to tobacco shops from the centroid of the territorial authority - which is a possible variable. But instead we could use density of shops per territorial authority!
Here, i will use open street map to calculate a density. I have downloaded the data from Geofabrik
Reading layer `gis_osm_pois_a_free_1' from data source
`C:\Users\Andy\OneDrive - University College London\Teaching\Guest\Oxford_24\Spatial analysis of public health data\prac4_data\new-zealand-latest-free.shp\gis_osm_pois_a_free_1.shp'
using driver `ESRI Shapefile'
Simple feature collection with 59185 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -176.6404 ymin: -52.59086 xmax: 178.5443 ymax: -34.42668
Geodetic CRS: WGS 84
Now let’s intersect with the territorial authority boundaries and calculate a density.
Note that the districts object is in the correct CRS, however i beleive this is due to naming differences so we will transform it just incase.
ta <- ta %>%st_transform(., 2135)stores_joined <- ta %>%mutate(n =lengths(st_intersects(., osm_pois_filter)))%>% janitor::clean_names()%>%#calculate areamutate(area=st_area(.))%>%#then density of the points per wardmutate(density=n/area)
Now, we could use this in our model!
On the 1st July 2024 New Zealand intends to reduce the number of tobacco retailers from 6,000 to just 599! With a maximum number per area according to the table set on Ministry of Health website.