Chapter 2 Introduction to R
2.1 Learning outcomes
By the end of this practical you should be able to:
- Execute basic processing in R
- Examine, clean and manipulate comma seperate value (
.csv) data - Examine, clean and manipulate and plot spatial (
.shp) data - Produce interactive maps
- Evaluate the benefits of different data manipulation and mapping techniques
2.2 Homework
Outside of our schedulded sessions you should be doing around 12 hours of extra study per week. Feel free to follow your own GIS interests, but good places to start include the following:
Assignment
This week you need to assess the validity of your topic in terms of data suitability, then sketch out an introduction and literature review including academic and policy documents (or any reputable source).
Reading
This week:
- Chapter 2 “Geographic data in R” from Geocomputation with R by Lovelace, Nowosad and Muenchow (2020).
Remember this is just a starting point, explore the reading list, practical and lecture for more ideas.
2.3 Recommended listening
Some of these practicals are long, take regular breaks and have a listen to some of our fav tunes each week.
Adam. Recommended listening this week comes courtesy of “Pound for pound the best rock band on the planet at the minute. In my, not so humble opinion.” – Jake Burns, Stiff Little Fingers. Yes, it’s the Wildhearts and I can confirm that they are the greatest rock band on the planet! Wrap your ears around this:
2.4 Introduction
This practical is LONG but it will take you from not knowing much about R to making freaking cool interactive maps in one practical. As you can imagine, this will be a steep learning curve.
I will give you all the code you need, it’s your job to read through the text very carefully and try to understand what bits of code are doing as you go.
There will be bits of code you don’t fully understand. Don’t worry, the key is to revisit later and try to work out what is going on then. Learning R is a long and iterative process and this is just the start…
If you want to learn more about R and indeed download the latest version for your own use, then visit the R project pages
The Wikipedia page for those who want to know a little of the history of R can be found here
There is an almost endless supply of good R tutorials on the web. If you get stuck or want to learn even more R (and why would you not want to?!), I’d recommend trying some of the following R Tutorial websites:
If you want to really be up to date with the state of the art in R, then bookdown is a fantastic resource. It features free books by some of the pre-eminent names in the R scene — I would urge you to go and take a look.
2.4.1 Online forums are your friend!!
With almost every problem you encounter with R, someone else will have had the same problem before you and posted it on a forum –– someone will then post a solution below.
My usual route is to Google the problem and I’ll then be directed to a post, usually on Stack Overflow, Stack Exchange or Cross Validated. When doing so try to think about the minimal working (or not working) example (MWE), by this i mean remove anything very specific to your problem. I’ve rarely not found a solution to a problem this way.
2.4.2 Health warning
Beware of posting questions on these forums yourself – contributors to these forums (especially the R ones!), whilst almost always extremely knowledgeable about R, have a bit of a reputation for being insert familiar pejorative term for less-than-polite-human-being here! As you might expect, people who have enough time to become total experts in R, have little time to work on their social skills!! Fortunately though, some other poor chump has usually taken that hit for you and you can still find a useful answer to your problem.
If you are specifically more interested in the spatial side of R, then Alex Singleton and Chris Brunsdon at the Universities of Liverpool and Maynooth also have a number of very useful R Spatial Tutorials – http://rpubs.com/alexsingleton/ & http://rpubs.com/chrisbrunsdon/
Robin Lovelace in Leeds is also frequently at the bleeding edge of developments in R spatial stuff, so keep an eye on his website. Robin has also made a book on GeoComputation in R, which you should definitely read! — https://geocompr.robinlovelace.net/
These websites are also very very good: https://pakillo.github.io/R-GIS-tutorial/ and http://www.maths.lancs.ac.uk/~rowlings/Teaching/UseR2012/cheatsheet.html
2.4.3 R and RStudio
When you download and install R, you get the R Graphical User Interface (GUI) as standard (below). This is fine and some purists prefer using the clean, unfussy command-line original, but it has some limitations such as no graphical way to view data tables or keep track of what is in your working directory (there are a number of others too).
Fortunately there are a number of software environments that have been developed for R to make it a little more user-friendly; the best of these by a long way is RStudio. RStudio can be downloaded for free from https://www.rstudio.com/. We covered the RStudio layout last week.
2.4.4 Getting started
If you are some kind of masochist, you are welcome to use the bundled R GUI for all of your work. If pain is not your thing, then for this practical (and future practicals) I will assume that you are using RStudio.
- From the start menu on your computer, find and run RStudio
Once RStudio has opened, the first thing we will do is create a new project – projects enable you to organise your work effectively and store all of the files you create and work with for a particular task.
To create a new project (and this will vary a little depending on the version of RStudio you are using) select File > New Project
Select Start a project in a brand new working directory and create a new project in a directory of a new ‘wk2’ directory on your N: drive:
My file directory (the second box here) will be different to yours as this is my teaching resources folder. Keep yours simple N:/GIS/wk2.
Setting up a project is extremely useful as it lets you easily access your data and files…for example….the flytipping .csv we used last week is stored at the file path
However as i’ve set my R project up in the CASA0005repo folder with different data folders for each week i can just use:
If i had the .csv file in the same folder as my project i could just use
You can run this in the Console area now or within a script which we will now go over…
I’d strongly recommend you think about how you will store data within your project. Is it sensible to just dump all your data into the project folder or perahps create a new folder (either in R) or how you would normally do so in Windows / OS X and keep your raw data in that folder…like i have done…Here you can see that i’m in my project folder (red box on the right) and i’ve made new folders for all my data (each practical here) and images that are shown throuhgout….nice and organised!
2.4.5 Basics
- R has a very steep learning curve, but hopefully it won’t take long to get your head around the basics. For example, at its most simple R can be used as a calculator. In the console window (bottom left), just type the following and press enter:
## [1] 6or
## [1] 100As you can see R performs these calculations instantly and prints the results in the console. This is useful for quick calculations but less useful for writing scripts requiring multiple operations or saving these for future use.
To save your scripts, you should create a new R Script file. Do this now: Select File > New File > R Script.
The R Script should open up on the top-left of your GUI. From now on type everything in this R script file and save it
2.4.6 Scripts and some basic commands
- Usually one of the first things to do when starting a new R Script is to check that you are in the correct working directory. This is important especially if you are working on multiple projects in different locations. To do this type the following into your new empty R Script:
## [1] "C:/Users/Andy/OneDrive - University College London/Teaching/CASA0005repo"To run this line, hold Ctrl (Cmd on a Mac) and press the Return(↲) key (if you are in the standard R installation, you would run your script with Ctrl R). You should now see your current working directory appear in the console.
Because of the new project we have already set up, this working directory should be correct, but if for any reason we wanted to change the working directory, we would use the
setwd()function. For example, we wanted to change our directory to the documents folder on the C drive, we could run (don’t do this now):
When we are sure we are working in the correct working directory, we can save our script by clicking on the save icon on the script tab. Save your script as something like “wk2_part1” and you will see it appear in your files window on the right hand side. As you build up a document of R code, you should get into the habit of saving your script periodically in case of an unexpected software crash.
We can now begin to write a script without the need to run each line every time we press enter. In the script editor type:
## [1] 3Select (highlight) the three lines and run all three lines with Ctrl Return(↲). You will notice the lines appear in the console (the other window). If you type C and press enter in the console (C and then ctrl return in the script window) you should have the number 3 appear. From now on I recommend you type all the commands below in the script first and then run them. Copying and pasting from this document won’t necessarily work.
You will also notice that in RStudio, values A, B and C will appear in your workspace window (top right). These variables are stored in memory for future use. Try giving A and B different values and see what happens. What about if you use lower case letters?
You have just demonstrated one of the powerful aspects of R, which is that it is an object oriented programming language. A, B and C are all objects that have been assigned a value with the <- symbol (you can also use the = sign, but it operates slightly differently to <- in R, plus the arrow assignment has become standard over the years. Use alt - to type it automatically). This principle underlies the whole language and enables users to create ever more complex objects as they progress through their analysis. If you type:
## [1] "A" "all_pkgs" "B" "C" "con" "mycsv" "session"
## [8] "shape"R will produce a list of objects that are currently active.
will remove the object A from the workspace (do ls() again to check this or look in your workspace window).
2.4.7 Functions
- Both
rm()andls()are known as functions. Functions are the other fundamental aspect to the R language. Functions can be thought of as single or multiple calculations that you apply to objects. They generally take the form of…(don’t run these)
Where the object is some form of data and the arguments parameterise what the function will do.
You could save the ouput to a new object using something like…
- You can write your own functions to carry out tasks (and we’ll come onto that in subsequent practical sessions), but normally you will just used one of the virtually infinite number of functions that other people have already written for us.
2.4.8 Basic plotting
One common function is the plot() function for displaying data as a graphical output. Add these lines to your script and run them as before and you can see some plot() outputs:
#create some datasets, first a vector of 1-100 and 101-200
Data1 <- c(1:100)
Data2 <- c(101:200)
#Plot the data
plot(Data1, Data2, col="red")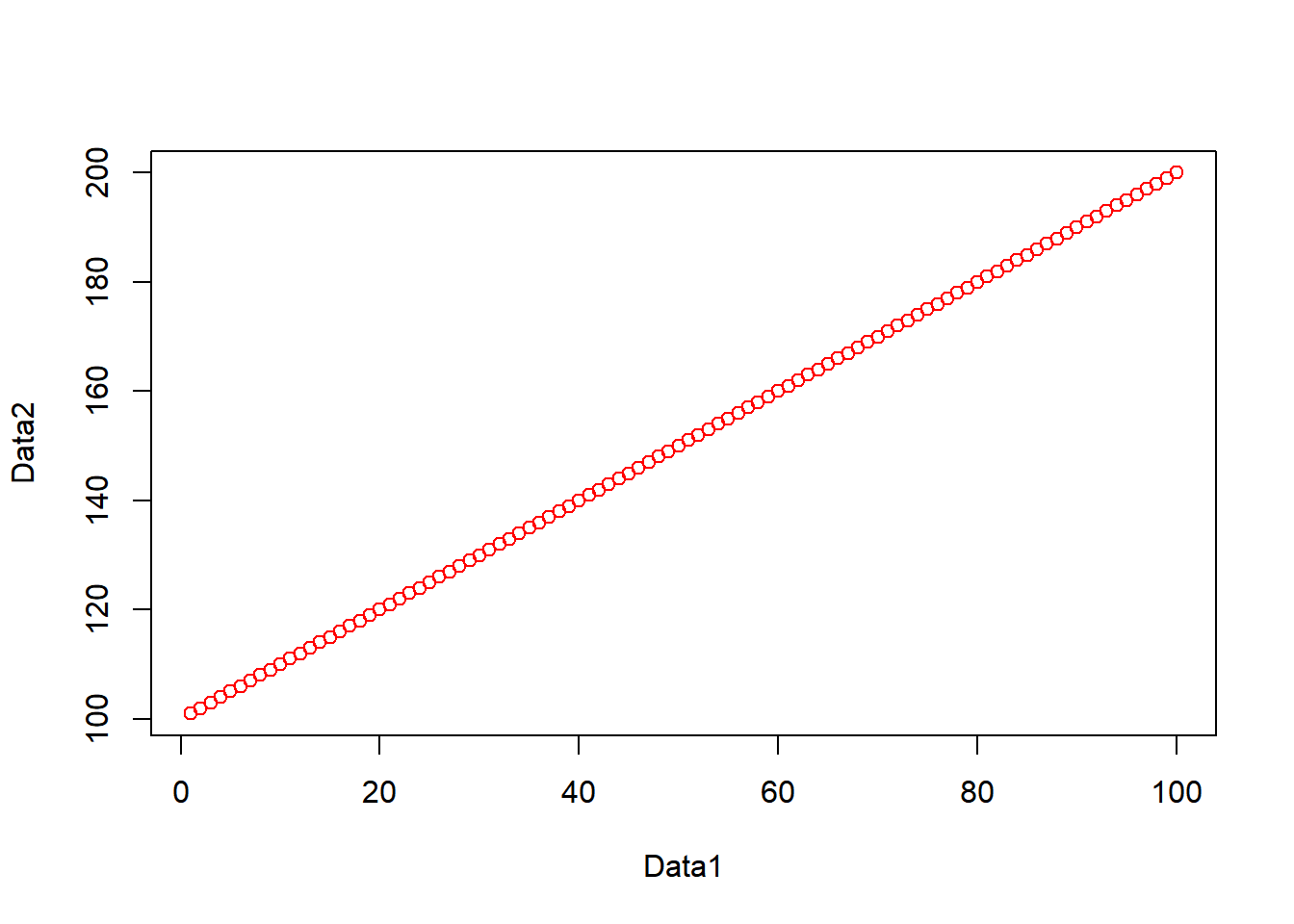
#just for fun, create some more, this time some normally distributed
#vectors of 100 numbers
Data3 <- rnorm(100, mean = 53, sd=34)
Data4 <- rnorm(100, mean = 64, sd=14)
#plot
plot(Data3, Data4, col="blue")
- In the code above, you will have noticed the
#symbol. This signifies that whatever comes after it on that line is a comment. Comments are ignored by the R console and they allow you to annotate your code so that you know what it is doing. It is good programming practice to comment your code extensively so that you can keep track of what your scripts are for.
Warning Heed our advice now and comment your code it will save you time in the future!
2.4.9 Help
- The previous lines of code also demonstrated a number of functions:
c()concatenates a string of numbers together into a vector. 1:100 means produce the integers between and including 1:100, theplot()function plots the two data objects and includes a parameter to change the colour of the points. To understand what a function does, you can consult the R Help system. Simply type a question mark and then the function name; for example:
- In RStudio you will see the help file appear in the Help window in the bottom right of the GUI. Here you can also search for the help files for other functions in the search bar.
2.4.10 Data types
- Objects in R can exist as a number of different data types. These include a matrix, a vector, a data frame and a list. For the purposes of this practical we will focus on data frames. These are the most flexible data format in R (although tibbles are now becoming popular as well — they are just more flexible versions of data frames, for example they can have a list as a column). Data frames can be conceptualised in a similar way to a spreadsheet with data held in rows and columns. They are the most commonly used object type in R and the most straightforward to create from the two vector objects we just created.
- If you have a very large data frame (thousands or millions of rows) it is useful to see only a selection of these. There are several ways of doing this:
## Data1 Data2
## 1 1 101
## 2 2 102
## 3 3 103
## 4 4 104
## 5 5 105
## 6 6 106## Data1 Data2
## 95 95 195
## 96 96 196
## 97 97 197
## 98 98 198
## 99 99 199
## 100 100 200You can also view elements of your data frame in RStudio by simply clicking on it in the top-right Environment window:
2.4.11 Elements of a data frame
- When programming you will frequently want to refer to different elements in a data frame or a vector/list. To select elements of a data frame, or subset it, you can refer specifically to ranges or elements of rows and columns. These are accessed using the single square bracket operator [], with the form:
Rows are always referenced first, before the comma, columns second, after the comma.
- Try the subsetting your df data frame with the following commands to see what is returned:
## [1] 1 2 3 4 5 6 7 8 9 10## Data1 Data2
## 5 5 105
## 6 6 106
## 7 7 107
## 8 8 108
## 9 9 109
## 10 10 110
## 11 11 111
## 12 12 112
## 13 13 113
## 14 14 114
## 15 15 115## [1] 102 103 106## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
## [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
## [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
## [91] 91 92 93 94 95 96 97 98 99 100- You will note that the column headings are the names of the original objects creating the data frame. We can change these using the
colnames()function:
To select or refer to these columns directly by name, we can either use the $ operator, which takes the form data.frame$columnName, e.g.
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
## [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
## [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
## [91] 91 92 93 94 95 96 97 98 99 100or we can use the double square bracket operator [[]], and refer to our column by name using quotes e.g.
## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
## [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
## [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
## [91] 91 92 93 94 95 96 97 98 99 100This again is useful if you have a lot of columns and you wish to efficiently extract one of them.
2.5 Reading data into R
One of the most tedious things a spatial analyst / data scientist has to do is clean their data so it doesn’t cause problems for the software later. In the past, we would have needed to do this by hand — these days, we can use software to do much of this for us.
I will now give you two options to arrive at a nice cleaned dataset. If you have issues with software packages etc, you might still need to via the old skool route, however, the new skool route will be much more satisfying if it works!
For this example we are going to use the London Datastore Catalogue.
Go to: https://data.london.gov.uk/dataset/f33fb38c-cb37-48e3-8298-84c0d3cc5a6c and download the excel document for ward profiles.
2.5.1 Old skool cleaning
Open the
ward-profiles-excel-version.xlsfile in Excel, and save asLondonData.csvinto your wk2/RProject folder.Open your new
.csvfile in Excel. There might be some non-numeric values inside numeric columns which will cause problems in your analysis. These need to be removed before proceeding any further. To remove these, you can use the replace function in Excel. In the home tab under ‘Editing’ open up the find and replace dialogue box and enter the following into the find box:
#VALUE! n/a
Leave the replace box empty each time and click Replace All to remove these from your file, before saving the file again.
- Once you have cleaned out all of the trixy characters from the file, to read it into R, we will use the
read.csv()function:
Note, I’ve made an R project for all these practicals, which is why my file path starts with
prac2_data/. If you save the.csvin the same folder as the.Rprojthen you can just use:
If you look at the read.csv() help file - ?read.csv - you will see that we can actually include many more parameters when reading in a .csv file. For example, we could read in the same file as follows:
# by default in R, the file path should be defined with /
#but on a windows file system it is defined with \.
#Using \\ instead allows R
#to read the path correctly – alternatively, just use /
LondonDataOSK<- read.csv("prac2_data/ward-profiles-excel-version.csv",
header = TRUE, sep = ",", encoding = "latin1")This would specify that the first row of the file contains header information; and the values in the file are separated with commas (not ; or : as can be the case sometimes).
2.5.2 Here
However, this is also another more straightforward way to read in files that was devloped in 2017 to make it more intuitive to find and load files using the here package. You need to install and load it:
## here() starts at C:/Users/Andy/OneDrive - University College London/Teaching/CASA0005repoThink of here as a command that is just poitning to a file path, to find out where is pointing use…
## [1] "C:/Users/Andy/OneDrive - University College London/Teaching/CASA0005repo"This is my working directory for my book project! Now i can use this to load my data that is in my practical 2 folder just like this….
LondonDataOSK<- read.csv(here::here("prac2_data","ward-profiles-excel-version.csv"),
header = TRUE, sep = ",",
encoding = "latin1")This just removes any need for ever using a / or \\ in your file path. As with everything in code, there is no right way, use what suits you.

2.5.3 New skool cleaning
To clean our data as we read it in, we are going to use a package (more about packages later — for now, just think about it as a lovely gift from the R gods) called readr which comes bundled as part of the tidyverse package.

If you want to find out more about the tidyverse (and you really should) then you should start with the tidyverse website — the tidyverse package contains almost everything you need to become a kick-ass data scientist. ‘Tidy’ as a concept in data science is well worth reading about and you should start here with Hadley Wickham’s paper
Anyway, first install the package:
Now we can use the readr package… which comes bundled as part of the tidyverse and allows loads of data manipulation …for example…

Here we will use it to just read in a .csv file (directly from the web this time — read.csv can do this too) and clean text characters out from the numeric columns before they cause problems:
library(tidyverse)
#wang the data in straight from the web using read_csv,
#skipping over the 'n/a' entries as you go...
LondonData <- read_csv("https://files.datapress.com/london/dataset/ward-profiles-and-atlas/2015-09-24T14:21:24/ward-profiles-excel-version.csv",
locale = locale(encoding = "latin1"),
na = "n/a")Note the use of read_csv here as opposed to read.csv. They are very similar, but read_csv is just a bit better. Read this for more information. Also, for those python fans out there —IT’S NOT THE SAME FUNCTION AS READ_CSV IN PYTHON
What is locale = locale(encoding = "latin1")…good question…it is basically the encoding of the data (how it is stored). There are a few different formats such as UTF-8 and latin1. In latin1 each character is 1 byte long, in UTF-8 a character can consist of more than 1 byte. To my knowledge the default in R is encoded as latin1, but readr (the package we are using to read in the .csv is UTF-8 so we have to specify it.
2.5.4 Examining your new data
- Your new data has been read in as a data frame / tibble (a tibble is just a data frame with a few extra bells and whistles). If you ever need to check what data type your new data set is, we can use the
class()function:
## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"We can also use the class function within another two functions (cbind() and lapply()) to check that our data has been read in correctly and that, for example, numeric data haven’t been read in as text or other variables. Run the following line of code:
You should see that all columns that should be numbers are read in as numeric. Try reading in LondonData again, but this time without excluding the ‘n/a’ values in the file, e.g.
LondonData <- read_csv("https://files.datapress.com/london/dataset/ward-profiles-and-atlas/2015-09-24T14:21:24/ward-profiles-excel-version.csv",
locale = locale(encoding = "latin1"))Now run the datatypelist function again — you should see that some of the columns (those the n/a values in) have been read in as something other than numeric. This is why we need to exclude them. Isn’t readr great for helping us avoid reading in our numeric data as text!
To show this print the values in the column % children in reception year who are obese - 2011/12 to 2013/14 the column Mean Age - 2013
# col has n/a and is not numeric
LondonData$`% children in reception year who are obese - 2011/12 to 2013/14`## [1] "11.1" "13.3" "10.0" "12.3" "12.8" "12.6" "11.5" "16.2" "16.2" "15.0"
## [11] "11.4" "12.6" "14.8" "17.2" "15.6" "12.2" "12.9" "12.8" "10.8" "11.9"
## [21] "12.2" "12.6" "10.0" "11.3" "7.9" "10.9" "6.6" "6.3" "8.7" "11.2"
## [31] "7.4" "4.5" "11.3" "7.8" "9.0" "7.9" "8.5" "9.8" "9.1" "9.1"
## [41] "11.8" "8.5" "9.7" "6.1" "11.8" "11.1" "10.1" "14.0" "11.5" "10.9"
## [51] "13.4" "10.4" "13.3" "8.2" "15.2" "11.0" "8.7" "9.1" "10.4" "17.1"
## [61] "8.3" "10.8" "8.3" "13.2" "15.6" "10.5" "15.8" "11.6" "5.8" "11.9"
## [71] "13.7" "11.5" "13.0" "9.9" "10.7" "17.0" "10.6" "13.1" "11.2" "9.2"
## [81] "15.0" "7.3" "8.0" "10.5" "5.8" "4.2" "6.0" "7.1" "7.8" "9.1"
## [91] "8.4" "9.6" "11.4" "4.4" "7.4" "7.1" "11.1" "9.2" "10.4" "6.1"
## [101] "9.2" "3.9" "6.8" "10.9" "12.0" "11.6" "9.0" "3.5" "n/a" "10.7"
## [111] "n/a" "12.0" "5.3" "9.0" "6.5" "13.4" "10.9" "12.6" "12.3" "13.8"
## [121] "6.1" "10.3" "11.5" "13.2" "11.5" "9.4" "9.6" "8.9" "10.2" "13.9"
## [131] "10.6" "4.5" "11.3" "11.2" "8.1" "7.7" "14.6" "8.8" "9.1" "11.6"
## [141] "13.8" "10.5" "11.1" "12.6" "11.6" "11.1" "10.0" "14.0" "6.2" "9.9"
## [151] "11.1" "11.0" "13.7" "9.1" "7.1" "11.4" "12.9" "5.3" "8.8" "12.1"
## [161] "14.1" "12.3" "11.6" "11.6" "14.8" "14.3" "7.4" "7.8" "9.3" "10.8"
## [171] "12.0" "9.0" "17.6" "14.1" "16.3" "8.6" "14.5" "8.9" "12.8" "13.2"
## [181] "11.0" "16.7" "12.0" "9.5" "9.7" "10.8" "13.4" "14.7" "6.6" "16.6"
## [191] "6.8" "12.8" "10.5" "6.8" "12.1" "13.8" "14.1" "11.1" "11.0" "11.5"
## [201] "7.0" "14.1" "12.8" "16.9" "14.0" "15.4" "15.0" "12.1" "17.4" "8.9"
## [211] "10.6" "13.7" "14.4" "10.7" "13.5" "14.8" "14.6" "10.7" "10.1" "18.2"
## [221] "12.9" "13.5" "10.7" "14.8" "15.8" "6.4" "9.5" "11.1" "12.8" "8.3"
## [231] "12.1" "8.7" "10.3" "8.0" "9.1" "9.1" "7.7" "14.5" "10.7" "12.5"
## [241] "10.5" "4.5" "10.6" "14.8" "2.4" "4.6" "7.8" "3.8" "8.2" "2.7"
## [251] "14.2" "17.2" "11.1" "10.7" "5.8" "13.9" "16.5" "13.8" "16.2" "12.0"
## [261] "7.1" "13.1" "11.3" "10.9" "9.8" "12.7" "6.8" "4.8" "8.1" "11.6"
## [271] "10.4" "10.9" "10.4" "6.4" "10.5" "6.0" "9.5" "9.7" "9.3" "11.8"
## [281] "7.3" "8.0" "9.0" "11.0" "10.5" "14.3" "12.1" "7.7" "9.7" "12.8"
## [291] "3.9" "10.6" "9.7" "13.6" "10.2" "11.5" "11.3" "10.4" "6.8" "11.5"
## [301] "9.8" "10.3" "6.4" "11.3" "5.9" "10.0" "12.8" "9.0" "7.0" "9.3"
## [311] "4.1" "8.3" "9.8" "9.3" "10.9" "7.4" "12.3" "10.0" "5.9" "10.4"
## [321] "11.0" "11.7" "12.6" "6.7" "6.6" "12.7" "12.7" "14.5" "13.1" "14.0"
## [331] "13.5" "10.5" "9.0" "11.8" "10.8" "9.3" "10.7" "10.7" "8.4" "9.7"
## [341] "7.3" "9.9" "12.4" "13.0" "9.1" "12.9" "11.8" "6.3" "11.4" "7.7"
## [351] "13.7" "8.6" "13.9" "8.7" "11.4" "9.1" "9.1" "n/a" "n/a" "5.2"
## [361] "14.0" "n/a" "11.0" "6.4" "13.3" "n/a" "12.0" "n/a" "n/a" "n/a"
## [371] "n/a" "n/a" "n/a" "n/a" "7.7" "7.6" "4.6" "6.5" "3.8" "9.8"
## [381] "8.1" "4.9" "5.2" "6.0" "11.3" "6.7" "5.9" "2.9" "4.2" "4.9"
## [391] "3.3" "15.6" "9.9" "12.7" "12.0" "12.9" "15.2" "13.3" "9.9" "9.1"
## [401] "10.8" "9.9" "10.0" "8.8" "15.0" "13.2" "9.5" "9.6" "9.7" "8.9"
## [411] "13.6" "15.4" "11.9" "9.6" "9.8" "10.5" "6.8" "12.2" "13.4" "9.0"
## [421] "10.6" "7.3" "8.6" "12.0" "15.6" "9.7" "13.7" "10.6" "11.3" "12.6"
## [431] "4.1" "6.2" "10.5" "11.9" "n/a" "13.5" "12.4" "5.1" "12.7" "14.6"
## [441] "9.3" "4.7" "10.9" "12.4" "2.0" "11.9" "6.4" "n/a" "5.5" "4.2"
## [451] "13.0" "13.0" "15.0" "14.3" "12.2" "13.4" "10.7" "10.4" "16.2" "10.7"
## [461] "9.5" "12.6" "12.8" "10.9" "13.0" "14.7" "12.4" "11.3" "10.2" "14.5"
## [471] "11.5" "7.6" "9.6" "13.6" "7.9" "6.9" "10.9" "12.2" "11.3" "9.8"
## [481] "13.0" "9.7" "11.8" "12.6" "7.5" "14.9" "8.9" "8.9" "5.6" "9.7"
## [491] "9.5" "4.8" "5.0" "5.6" "5.0" "5.3" "7.8" "6.4" "9.6" "3.5"
## [501] "5.3" "4.7" "4.0" "4.7" "5.8" "7.4" "3.2" "5.3" "9.3" "11.9"
## [511] "16.3" "11.4" "12.8" "14.1" "5.9" "16.4" "19.0" "14.3" "15.0" "13.7"
## [521] "14.5" "15.9" "9.2" "9.8" "10.3" "11.2" "10.2" "8.5" "13.2" "6.6"
## [531] "6.3" "8.6" "7.9" "6.4" "5.9" "7.1" "4.6" "11.5" "8.5" "9.1"
## [541] "9.5" "8.2" "8.3" "8.0" "7.2" "8.3" "10.0" "8.0" "15.5" "14.5"
## [551] "10.8" "14.3" "10.6" "12.5" "12.8" "12.5" "13.4" "11.8" "9.0" "12.4"
## [561] "10.7" "15.2" "14.2" "14.6" "13.4" "10.8" "11.9" "10.1" "8.4" "8.9"
## [571] "9.4" "10.8" "6.9" "8.1" "10.0" "10.3" "10.7" "11.2" "11.4" "13.4"
## [581] "9.9" "10.7" "11.5" "11.5" "12.0" "5.5" "8.2" "9.8" "7.0" "7.5"
## [591] "10.1" "10.9" "13.7" "4.1" "3.4" "11.1" "11.8" "12.7" "7.8" "6.6"
## [601] "4.6" "10.6" "8.6" "9.6" "12.4" "8.5" "9.5" "12.2" "14.6" "13.8"
## [611] "10.9" "11.6" "n/a" "6.0" "9.1" "8.5" "10.0" "11.0" "7.5" "12.6"
## [621] "13.1" "10.0" "13.5" "11.7" "n/a" "11.1" "13.6" "9.5" "11.6" "12.2"
## [631] "7.8" "9.8" "11.1" "11.2" "12.7" "13.2" "13.3" "10.2" "11.1" "9.6"
## [641] "10.3" "9.6" "11.2" "10.6" "9.2" "6.0" "11.5" "11.0" "9.0" "12.5"
## [651] "10.6" "5.7" "12.8" "8.1" "12.7" "10.6" "9.2" "11.1" "10.8" "9.4"## [1] 41.3 29.5 33.8 33.0 36.2 37.7 33.4 29.0 34.1 34.4 35.2 33.9 34.3 33.4 28.7
## [16] 34.8 34.5 35.3 38.9 33.7 36.1 32.1 36.3 38.3 37.2 37.1 39.1 39.1 33.0 37.1
## [31] 34.9 40.7 37.1 39.8 39.6 39.2 37.5 35.2 37.9 40.8 36.1 40.5 40.5 43.2 40.6
## [46] 37.3 37.7 39.4 40.2 40.5 34.9 39.6 38.8 42.2 33.6 39.2 42.4 38.2 41.8 32.0
## [61] 35.3 35.8 37.0 34.8 34.7 36.0 33.0 35.4 40.2 34.6 35.0 37.3 35.9 35.6 36.2
## [76] 32.2 35.1 34.9 35.8 35.6 33.7 41.8 40.9 39.6 37.5 41.6 42.6 37.2 40.6 38.2
## [91] 37.3 34.6 43.2 43.8 41.4 40.9 37.0 41.9 35.8 42.8 38.8 42.5 42.3 37.1 34.1
## [106] 37.3 34.6 36.0 37.6 37.0 39.9 35.1 40.0 36.2 35.5 36.1 31.5 34.0 33.1 36.8
## [121] 35.4 35.5 38.0 34.8 32.0 42.3 39.8 37.1 35.2 32.0 40.1 39.0 35.4 37.0 39.0
## [136] 42.0 33.1 43.2 39.9 35.6 34.2 36.3 35.2 33.7 33.9 35.1 36.7 35.3 37.5 37.4
## [151] 33.5 35.5 34.3 36.0 37.4 36.0 36.3 36.5 36.3 35.0 33.7 35.7 36.2 35.1 34.2
## [166] 33.2 36.9 36.6 36.2 40.6 36.9 40.7 32.0 33.7 32.3 41.3 33.9 41.4 35.4 32.7
## [181] 37.5 32.4 33.9 37.8 38.9 38.9 34.6 32.8 39.3 33.8 39.3 35.2 40.3 41.2 37.9
## [196] 36.2 32.8 33.1 36.7 37.9 32.9 34.0 38.0 29.8 30.7 31.3 33.4 29.6 32.5 34.0
## [211] 33.4 33.6 34.0 33.6 32.7 32.5 33.1 33.1 31.3 30.3 34.2 29.6 34.6 33.4 32.8
## [226] 34.8 34.1 36.3 34.0 35.3 34.4 35.5 34.2 33.9 38.6 35.8 37.1 33.9 34.5 33.6
## [241] 33.5 36.7 34.9 33.5 37.0 36.6 34.2 37.7 35.4 38.4 33.7 32.1 33.8 31.4 35.5
## [256] 33.7 32.2 34.7 32.8 34.3 37.9 40.3 36.0 34.9 35.9 39.5 41.7 40.6 36.8 37.4
## [271] 38.9 35.1 42.1 40.3 36.0 38.0 34.3 35.7 42.4 34.5 37.4 36.5 44.1 41.4 43.6
## [286] 36.0 42.8 40.4 38.9 38.5 41.3 40.5 43.2 39.9 37.3 42.7 38.3 40.0 44.3 33.6
## [301] 32.8 33.6 39.4 35.7 42.4 39.8 34.5 35.4 42.4 39.2 42.7 40.3 32.7 36.4 33.5
## [316] 39.2 33.2 34.8 40.2 32.3 33.9 35.3 34.6 37.6 37.9 34.1 36.7 31.7 34.8 36.4
## [331] 35.2 35.2 34.4 34.0 32.6 37.7 35.1 35.2 36.7 35.1 38.3 34.9 32.5 34.0 35.5
## [346] 34.8 33.6 35.5 33.6 35.0 33.5 35.6 33.7 35.2 35.9 35.2 34.2 37.7 39.2 38.4
## [361] 38.3 35.6 40.4 36.8 36.5 40.5 37.8 39.7 37.0 37.8 36.3 37.5 43.8 37.1 39.6
## [376] 38.9 38.3 37.3 33.6 38.3 37.6 37.1 37.9 33.4 34.0 39.9 40.6 33.6 37.7 37.3
## [391] 38.5 34.9 33.6 33.4 33.8 32.4 33.4 33.9 34.3 34.2 32.9 34.3 35.5 34.1 33.8
## [406] 34.5 35.6 34.0 33.1 34.7 32.9 33.9 34.6 35.9 33.0 36.6 35.4 35.5 31.3 35.4
## [421] 36.8 34.8 36.4 33.6 31.8 35.5 34.0 36.2 33.4 34.7 34.8 40.1 34.6 34.7 35.7
## [436] 33.8 35.8 38.6 33.6 35.7 39.1 38.6 34.8 36.4 38.0 36.6 34.6 41.9 37.6 34.2
## [451] 30.5 31.9 32.6 31.6 31.7 32.0 32.2 31.2 32.7 31.7 30.9 31.9 30.3 31.4 32.0
## [466] 30.9 29.7 31.5 31.2 32.7 35.4 37.9 38.0 33.9 37.1 37.9 30.7 36.1 37.2 38.2
## [481] 32.7 36.7 30.2 34.6 43.0 33.3 35.3 32.9 40.3 32.6 39.5 39.0 38.2 38.1 40.4
## [496] 40.3 39.8 38.4 38.2 38.7 36.9 38.2 35.3 38.7 36.6 39.0 38.2 36.8 39.5 33.4
## [511] 33.5 33.5 31.6 36.7 35.6 33.3 32.8 32.7 33.3 34.1 34.8 32.2 34.5 34.3 33.2
## [526] 33.1 33.3 33.9 34.2 36.8 38.5 38.0 40.2 39.1 39.4 41.6 41.1 34.7 39.3 36.0
## [541] 39.5 40.3 38.5 37.8 37.8 40.2 33.8 37.4 32.2 30.2 30.8 32.7 32.9 29.3 30.3
## [556] 31.1 30.3 29.6 31.0 31.4 34.3 30.7 31.3 32.7 30.7 32.3 32.3 33.4 42.3 40.2
## [571] 34.2 32.9 36.5 38.9 33.3 32.7 33.4 38.5 32.6 32.1 34.5 32.7 37.2 33.4 34.0
## [586] 34.2 34.2 33.1 36.4 34.1 34.5 33.9 33.6 35.0 33.0 34.1 32.8 36.0 34.6 34.1
## [601] 35.8 33.3 34.6 34.5 36.7 38.1 37.1 36.6 36.6 35.7 34.7 35.6 37.2 35.2 36.5
## [616] 35.2 37.6 34.5 39.1 37.9 40.2 38.2 38.2 34.3 38.8 41.3 33.2 36.9 38.9 35.3
## [631] 39.8 35.8 36.6 35.6 36.1 34.7 32.6 34.9 34.4 37.7 40.3 36.2 35.3 34.4 38.3
## [646] 36.9 33.9 34.5 36.3 31.4 35.5 38.3 33.8 38.3 31.1 34.5 34.4 36.7 35.6 39.6- It is also possible to quickly and easily summarise the data or look at the column headers using
## column1 column2
## Min. : 1.00 Min. :101.0
## 1st Qu.: 25.75 1st Qu.:125.8
## Median : 50.50 Median :150.5
## Mean : 50.50 Mean :150.5
## 3rd Qu.: 75.25 3rd Qu.:175.2
## Max. :100.00 Max. :200.0## [1] "Ward name"
## [2] "Old code"
## [3] "New code"
## [4] "Population - 2015"
## [5] "Children aged 0-15 - 2015"
## [6] "Working-age (16-64) - 2015"
## [7] "Older people aged 65+ - 2015"
## [8] "% All Children aged 0-15 - 2015"
## [9] "% All Working-age (16-64) - 2015"
## [10] "% All Older people aged 65+ - 2015"
## [11] "Mean Age - 2013"
## [12] "Median Age - 2013"
## [13] "Area - Square Kilometres"
## [14] "Population density (persons per sq km) - 2013"
## [15] "% BAME - 2011"
## [16] "% Not Born in UK - 2011"
## [17] "% English is First Language of no one in household - 2011"
## [18] "General Fertility Rate - 2013"
## [19] "Male life expectancy -2009-13"
## [20] "Female life expectancy -2009-13"
## [21] "% children in reception year who are obese - 2011/12 to 2013/14"
## [22] "% children in year 6 who are obese- 2011/12 to 2013/14"
## [23] "Rate of All Ambulance Incidents per 1,000 population - 2014"
## [24] "Rates of ambulance call outs for alcohol related illness - 2014"
## [25] "Number Killed or Seriously Injured on the roads - 2014"
## [26] "In employment (16-64) - 2011"
## [27] "Employment rate (16-64) - 2011"
## [28] "Number of jobs in area - 2013"
## [29] "Employment per head of resident WA population - 2013"
## [30] "Rate of new registrations of migrant workers - 2011/12"
## [31] "Median House Price (£) - 2014"
## [32] "Number of properties sold - 2014"
## [33] "Median Household income estimate (2012/13)"
## [34] "Number of Household spaces - 2011"
## [35] "% detached houses - 2011"
## [36] "% semi-detached houses - 2011"
## [37] "% terraced houses - 2011"
## [38] "% Flat, maisonette or apartment - 2011"
## [39] "% Households Owned - 2011"
## [40] "% Households Social Rented - 2011"
## [41] "% Households Private Rented - 2011"
## [42] "% dwellings in council tax bands A or B - 2015"
## [43] "% dwellings in council tax bands C, D or E - 2015"
## [44] "% dwellings in council tax bands F, G or H - 2015"
## [45] "Claimant rate of key out-of-work benefits (working age client group) (2014)"
## [46] "Claimant Rate of Housing Benefit (2015)"
## [47] "Claimant Rate of Employment Support Allowance - 2014"
## [48] "Rate of JobSeekers Allowance (JSA) Claimants - 2015"
## [49] "% dependent children (0-18) in out-of-work households - 2014"
## [50] "% of households with no adults in employment with dependent children - 2011"
## [51] "% of lone parents not in employment - 2011"
## [52] "(ID2010) - Rank of average score (within London) - 2010"
## [53] "(ID2010) % of LSOAs in worst 50% nationally - 2010"
## [54] "Average GCSE capped point scores - 2014"
## [55] "Unauthorised Absence in All Schools (%) - 2013"
## [56] "% with no qualifications - 2011"
## [57] "% with Level 4 qualifications and above - 2011"
## [58] "A-Level Average Point Score Per Student - 2013/14"
## [59] "A-Level Average Point Score Per Entry; 2013/14"
## [60] "Crime rate - 2014/15"
## [61] "Violence against the person rate - 2014/15"
## [62] "Deliberate Fires per 1,000 population - 2014"
## [63] "% area that is open space - 2014"
## [64] "Cars per household - 2011"
## [65] "Average Public Transport Accessibility score - 2014"
## [66] "% travel by bicycle to work - 2011"
## [67] "Turnout at Mayoral election - 2012"2.5.5 Data manipulation in R
Now we have some data read into R, we need to select a small subset to work on. The first thing we will do is select just the London Boroughs to work with. If you recall, the Borough data is at the bottom of the file.
2.5.5.1 Selecting rows
- Your borough data will probably be found between rows 626 and 658. Therefore we will first create a subset by selecting these rows into a new data frame and then reducing that data frame to just four columns. There are a few ways of doing this:
We could select just the rows we need by explicitly specifying the range of rows we need:
There is also a subset() function in R. You could look that up and see whether you could create a subset with that. Or, we could try a cool ‘data sciency’ way of pulling out the rows we want with the knowledge that the codes for London Boroughs start with E09 (the wards in the rest of the file start with E05).
Knowing this, we can use the grep() function which can use regular expressions to match patterns in text. Let’s try it!
Check it worked:
AWWMAHGAWD!!! Pretty cool hey?
What that function is saying is “grep (get) me all of the rows from the London Data data frame where the text in column 3 starts with (^) E09”
You will notice that you will have two rows at the top for the City of London. This is because it features twice in the data set. That’s fine, we can just drop this row from our dataset:
2.5.5.2 Selecting columns
- You will have noticed the use of square brackets above –– these are very useful in R. Refer back to points 19-21 above if you can’t remember how they work. The
c()function is also used here — this is the ‘combine’ function — another very useful function in R which allows arguments (in this case, column reference numbers) into a single value.
2.5.5.3 Renaming columns
- You will notice that the column names are slightly misleading as we are now working with boroughs rather than wards. We can rename the columns to something more appropriate using the
names()function (there are various other functions for renaming columns - for examplecolnames()if you want to rename multiple columns:
2.5.6 Plotting
plot(LondonBoroughs$Male.life.expectancy..2009.13,
LondonBoroughs$X..children.in.reception.year.who.are.obese...2011.12.to.2013.14)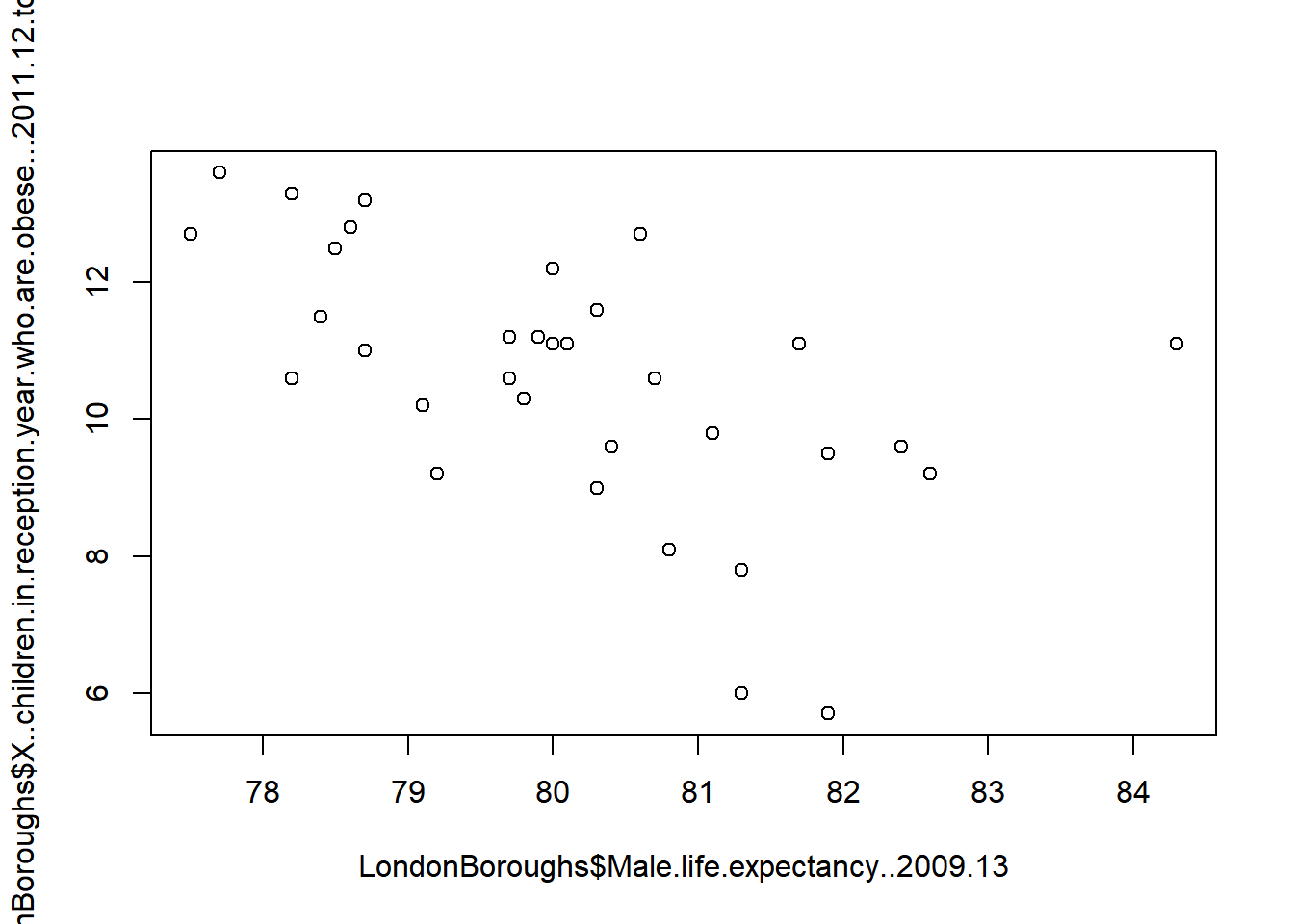
2.5.7 Pimp my graph!
Now, of course, because this is R, we can pimp this graph using something a bit more fancy than the base graphics functions:
2.5.8 Spatial Data in R
This next part of the practical applies the same principles introduced above to the much more complex problem of handling spatial data within R. In this workshop we will produce a gallery of maps using many of the plotting tools available in R. The resulting maps will not be that meaningful — the focus here is on sound visualisation with R and not sound analysis (I know one is useless without the other!). Good quality spatial analysis will come in the rest of the module.
Whilst the instructions are step by step you are encouraged to start deviating from them (trying different colours for example) to get a better understanding of what we are doing.
2.5.8.1 Packages
In this section we’ll require even more specialist packages, so I should probably spend some more time explaining what packages actually are! Packages are bits of code that extend R beyond the basic statistical functionality it was originally designed for. For spatial data, they enable R to process spatial data formats, carry out analysis tasks and create some of the maps that follow.
Bascially, without packages, R would be very limited. With packages, you can do virtually anything! One of the issues you will come across is that packages are being continually developed and updated and unless you keep your version of R updated and your packages updated, there may be some functions and options not available to you. This can be a problem, particularly with University installations which (at best) may only get updated once a year. Therefore, apologies in advance if things don’t work as intended!
- In R Studio all packages can be installed and activated in the ‘Packages’ tab in the bottom-right hand window:
- As with everything else in R though, we can also run everything from the command line. The first package we need to install for this part of the practical is
maptools–– either find and install it using the RStudio GUI or do the following:
There are a few other packages we’ll need to get to grips with. Some, like ggplot2 (one of the most influential R packages ever) are part of the tidyverse package we came across earlier. Others we will need to install for the first time.
install.packages(c("classInt", "tmap"))
# might also need these ones
install.packages(c("RColorBrewer", "sp", "rgeos",
"tmaptools", "sf", "downloader", "rgdal",
"geojsonio"))Now that the packages have been installed you will not have to repeat the above steps again (when you use your account in these cluster rooms). Open a new script and save it to your working directory as
wk2_maps.r. As before, type each of the lines of code into this window and then select and use the ctrl return keys to run them. Be sure to save your script often.The first task is to load the packages we have just installed. Note, you might have some issues with the OpenStreetMap package if your installation of java on your computer doesn’t match your installation of R –– e.g. if you have installed the 64bit version of R, you also need the 64bit version of java (same with the 32bit versions) — you may also need to install the package Rcpp separately and try again.
Install Java 64-bit from: https://java.com/en/download/manual.jsp
2.5.8.2 Background to spatial data in R
R has a very well developed ecosystem of packages for working with Spatial Data. Early pioneers like Roger Bivand and Edzer Pebesma along with various colleagues were instrumental in writing packages to interface with some powerful open source libraries for working with spatial data, such as GDAL and GEOS. These were accessed via the rgdal and rgeos packages. The maptools package by Roger Bivand, amongst other things, allowed Shapefiles to be read into R. The sp package (along with spdep) by Edzer Pebesma was very important for defining a series of classes and methods for spatial data natively in R which then allowed others to write software to work with these formats. Other packages like raster advanced the analysis of gridded spatial data, while packages like classInt and RColorbrewer facilitated the binning of data and colouring of choropleth maps.
Whilst these packages were extremely important for advancing spatial data analysis in R, they were not always the most straightforward to use — making a map in R could take quite a lot of effort and they were static and visually basic. However, more recently new packages have arrived to change this. Now leaflet enables R to interface with the leaflet javascript library for online, dynamic maps. ggplot2 which was developed by Hadley Wickam and colleagues radically changed the way that people thought about and created graphical objects in R, including maps, and introduced a graphical style which has been the envy of other software to the extent that there are now libraries in Python which copy the ggplot2 style!

Building on all of these, the new tmap (Thematic Map) package has changed the game completely and now enables us to read, write and manipulate spatial data and produce visually impressive and interactive maps, very easily. In parallel, the sf (Simple Features) package is helping us re-think the way that spatial data can be stored and manipulated. It’s exciting times for geographic information / spatial data science!
2.5.8.3 Making some choropleth maps
Choropleth maps are thematic maps which colour areas according to some phenomenon. In our case, we are going to fill some irregular polygons (the London Boroughs) with a colour that corresponds to a particular attribute.
As with all plots in R, there are multiple ways we can do this. The basic plot() function requires no data preparation but additional effort in colour selection/ adding the map key etc. qplot() and ggplot() (installed in the ggplot2 package) require some additional steps to format the spatial data but select colours and add keys etc automatically. Here, we are going to make use of the new tmap package which makes making maps very easy indeed.
- So one mega cool thing about R is you can read spatial data in straight from the internetz! Try this below for downloading a GeoJson file…it might take a few minutes…
Or you can do a manual download from the Office for National Statistics Open Geography Portal via Download > Shapefile — see point 7.
Pull out London using grep and the regex wildcard for ‘start of the string’ (^) to to look for the bit of the district code that relates to London (E09) from the ‘lad15cd’ column in the data slot of our spatial polygons dataframe
- Of course, we can also read in our data from a shapefile stored in a local directory:
#read the shapefile into a simple features object
BoroughMapSF <- st_read("prac1_data/statistical-gis-boundaries-london/ESRI/London_Borough_Excluding_MHW.shp")## Reading layer `London_Borough_Excluding_MHW' from data source `C:\Users\Andy\OneDrive - University College London\Teaching\CASA0005repo\prac1_data\statistical-gis-boundaries-london\ESRI\London_Borough_Excluding_MHW.shp' using driver `ESRI Shapefile'
## Simple feature collection with 33 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 503568.2 ymin: 155850.8 xmax: 561957.5 ymax: 200933.9
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.999601272 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defsBoroughMapSP <- LondonMap
#plot it very quickly usking qtm (quick thematic map) to check
#it has been read in correctly
qtm(BoroughMapSF)
- And naturally we can convert between simple features objects and spatialPolygonsDataFrames very easily:
## [1] "sf" "data.frame"## [1] "SpatialPolygonsDataFrame"
## attr(,"package")
## [1] "sp"2.5.8.4 Attribute data
OK, enough messing around, show us the maps!!
- Hold your horses, before be can create a map, we need to join some attribute data to some boundaries. Doing this on a
SPobject can be a bit of a pain, but I’ll show you here:
#join the data to the @data slot in the SP data frame
BoroughMapSP@data <- data.frame(BoroughMapSP@data,LondonData[match(BoroughMapSP@data[,"GSS_CODE"],LondonData[,"New.code"]),])
#check it's joined.
head(BoroughMapSP@data)- Joining data is a bit more intuitive with
merge():
An alternative to merge() would be to use a left_join() (like in SQL)
However, you would need to remove the duplicate City of London row afterwards
2.5.8.5 Making some maps
If you want to learn a bit more about the sorts of things you can do with tmap, then there are 2 vignettes that you can access here — I suggest you refer to these to see the various things you can do using tmap. Here’s a quick sample though:
- We can create a choropleth map very quickly now using
qtm()
## tmap mode set to plotting
You can also add a basemap and some other guff, if you wish…This part of the practical originally used the following code (do not run it):
tmap_mode("plot")
st_transform(BoroughDataMap, 4326)
london_osm <- tmaptools::read_osm(BoroughDataMap, type = "esri", zoom = NULL)
qtm(BoroughDataMap) +
tm_shape(BoroughDataMap) +
tm_polygons("Rate.of.JobSeekers.Allowance..JSA..Claimants...2015",
style="jenks",
palette="YlOrBr",
midpoint=NA,
title="Rate per 1,000 people",
alpha = 0.5) +
tm_compass(position = c("left", "bottom"),type = "arrow") +
tm_scale_bar(position = c("left", "bottom")) +
tm_layout(title = "Job seekers' Allowance Claimants", legend.position = c("right", "bottom"))However, there seems to be an issue with read_osm() that means even the example data won’t work. I’ve logged the issue on GitHub and stackexchange and will most likely get some pretty direct comments. Have a look:
- https://github.com/mtennekes/tmaptools/issues/17
- https://stackoverflow.com/questions/57408279/parameter-error-in-tmaptools-package-read-osm-when-using-example-data/57432541#57432541
So in the mean time i’ve made a bit of a workaround that uses the packages ggmap and ggplot… You can find this later on in this practical when we cover ggplot and extra map features in (Maps with extra features).
- How about more than one map, perhaps using different data breaks…
tm_shape(BoroughDataMap) +
tm_polygons(c("Average.Public.Transport.Accessibility.score...2014", "Violence.against.the.person.rate...2014.15"),
style=c("jenks", "pretty"),
palette=list("YlOrBr", "Purples"),
auto.palette.mapping=FALSE,
title=c("Average Public Transport Accessibility", "Violence Against the Person Rate"))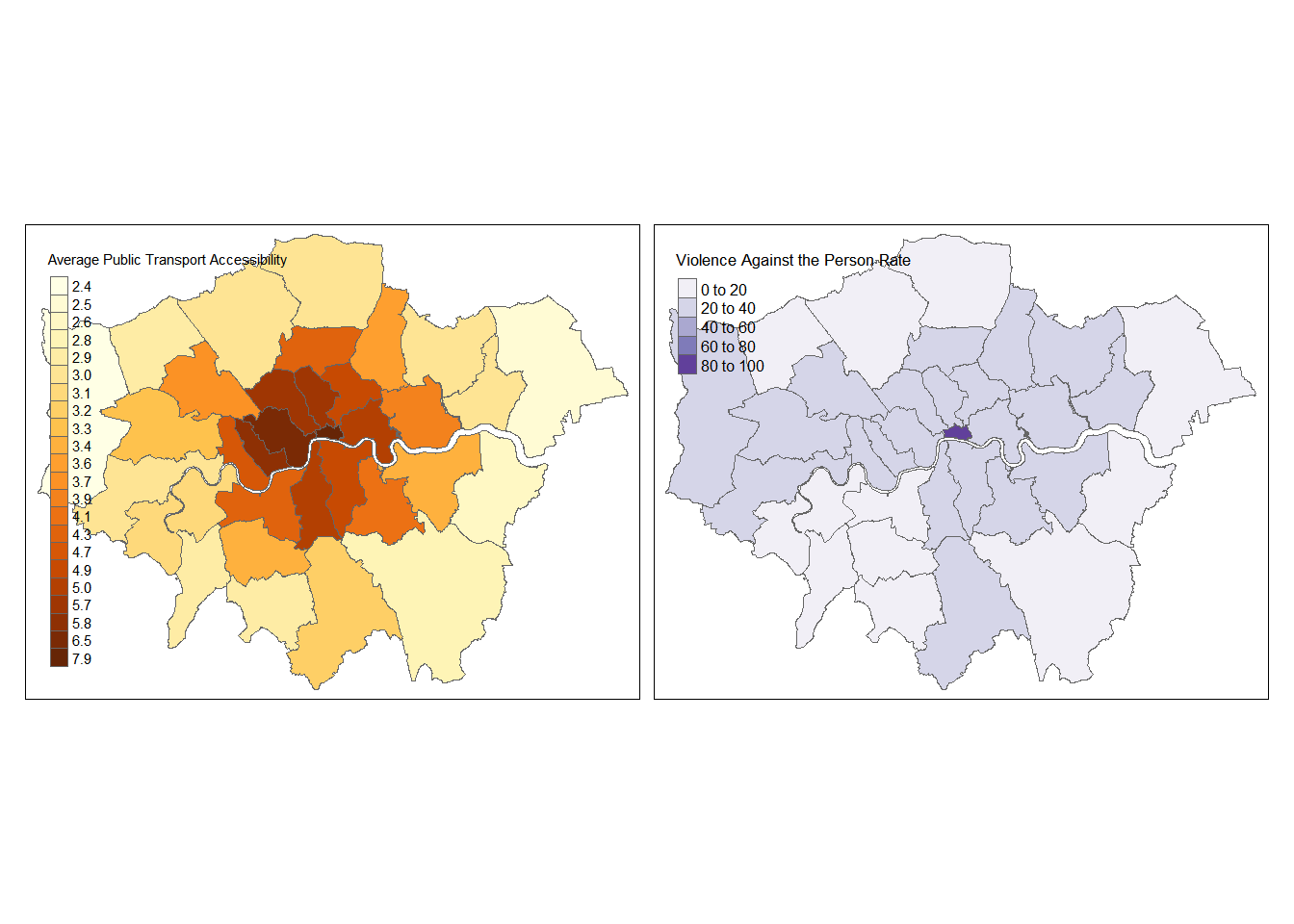
You will notice that to choose the colour of the maps, I entered some codes. These are the names of colour ramps from the RColourBrewer package which comes bundled with tmap. RColorBrewer uses colour palettes available from the colorbrewer2 website which is in turn based on the work of Cynthia Brewer and colleagues at Penn State University. Cynthia brewer has carried out large amount of academic research into determining the best colour palettes for GIS applications and so we will defer to her expertise here.
If you want to look at the range of colour palettes available, as we; as going to the ColorBrewer website, you can use the a little shiny app which comes bundled with tmaptools
library(shinyjs)
#it's possible to explicitly tell R which
#package to get the function from with the :: operator...
tmaptools::palette_explorer()tmapwill even let you make a FRICKING INTERACTIVE MAP!!! Oh yes, we can do interactive maps…!
2.5.8.6 Have a play around…
There are loads of options for creating maps with tmap — read the vignettes that have been provided by the developers of the package and see if you can adapt the maps you have just made — or even make some alternative maps using built in data.
- https://cran.r-project.org/web/packages/tmap/vignettes/tmap-nutshell.html * https://cran.r-project.org/web/packages/tmap/vignettes/tmap-modes.html
You should also read the reference manual on the package homepage
In fact, since I wrote this the tmap package has developed quite a bit more — have a look at some of the cool examples here
Have a play and see what cool shiz you can create!
This is an example from the BubbleMap folder on the tmap GitHub. Don’t worry about what GitHub is we will cover that soon.
# load spatial data included in the tmap package
data("World", "metro")
# calculate annual growth rate
metro$growth <- (metro$pop2020 - metro$pop2010) / (metro$pop2010 * 10) * 100
# plot
tm_shape(World) +
tm_polygons("income_grp", palette = "-Blues",
title = "Income class", contrast = 0.7, border.col = "gray30", id = "name") +
tm_text("iso_a3", size = "AREA", col = "gray30", root=3) +
tm_shape(metro) +
tm_bubbles("pop2010", col = "growth", border.col = "black",
border.alpha = 0.5,
breaks = c(-Inf, 0, 2, 4, 6, Inf) ,
palette = "-RdYlGn",
title.size = "Metro population (2010)",
title.col = "Annual growth rate (%)",
id = "name",
popup.vars=c("pop2010", "pop2020", "growth")) +
tm_format("World") +
tm_style("gray")2.6 Making maps using ggplot2
So as you have seen, it is possible to make very nice thematic maps with tmap. However, there are other options. The ggplot2 package is a very powerful graphics package that allows us to a huge range of sophisticated plots, including maps.
The latest development version of ggplot2 has support for simple features objects with the new geom_sf class (http://ggplot2.tidyverse.org/reference/ggsf.html), which, quite frankly, is bloody brilliant!
If you have not already done so, install and library the
ggplot2andrgeospackages (they should be installed automatically as part oftidyverseandtmappackages, but occasionally they need to be installed separately).Now there are two main ways in which you can construct a plot in
ggplot2:qplot()andggplot().qplotis short for ‘Quick plot’ and can be good for producing quick charts and maps, but is perhaps less good for constructing complex layered plots.ggplot()is better for building up a plot layer by layer, e.g.ggplot()+layer1+layer2, and so this is what we will use here.The important elements of any
ggplotlayer are the aesthetic mappings –– aes(x,y, …) –– which tell ggplot where to place the plot objects. We can imagine a map just like a graph with all features mapping to an x and y axis. All geometry (geom_) types in ggplot feature some kind of aesthetic mapping and these can either be declared at the plot level, e.g. (don’t run this)
or, more flexibly at the level of the individual geom_layer(), e.g.
- To begin our plot, we will start with the map layer –– we will generate this using the
geom_sf()function inggplot2:
library(ggplot2)
ggplot()+geom_sf(mapping = aes(geometry=geometry),
data = BoroughDataMap)+
theme_minimal()
- To colour your map, then just pass the name of the variable you want to map to the fill parameter in the aesthetics:
ggplot()+geom_sf(mapping = aes(geometry=geometry,
fill=Median.Household.income.estimate..2012.13.),
data = BoroughDataMap)+
theme_minimal()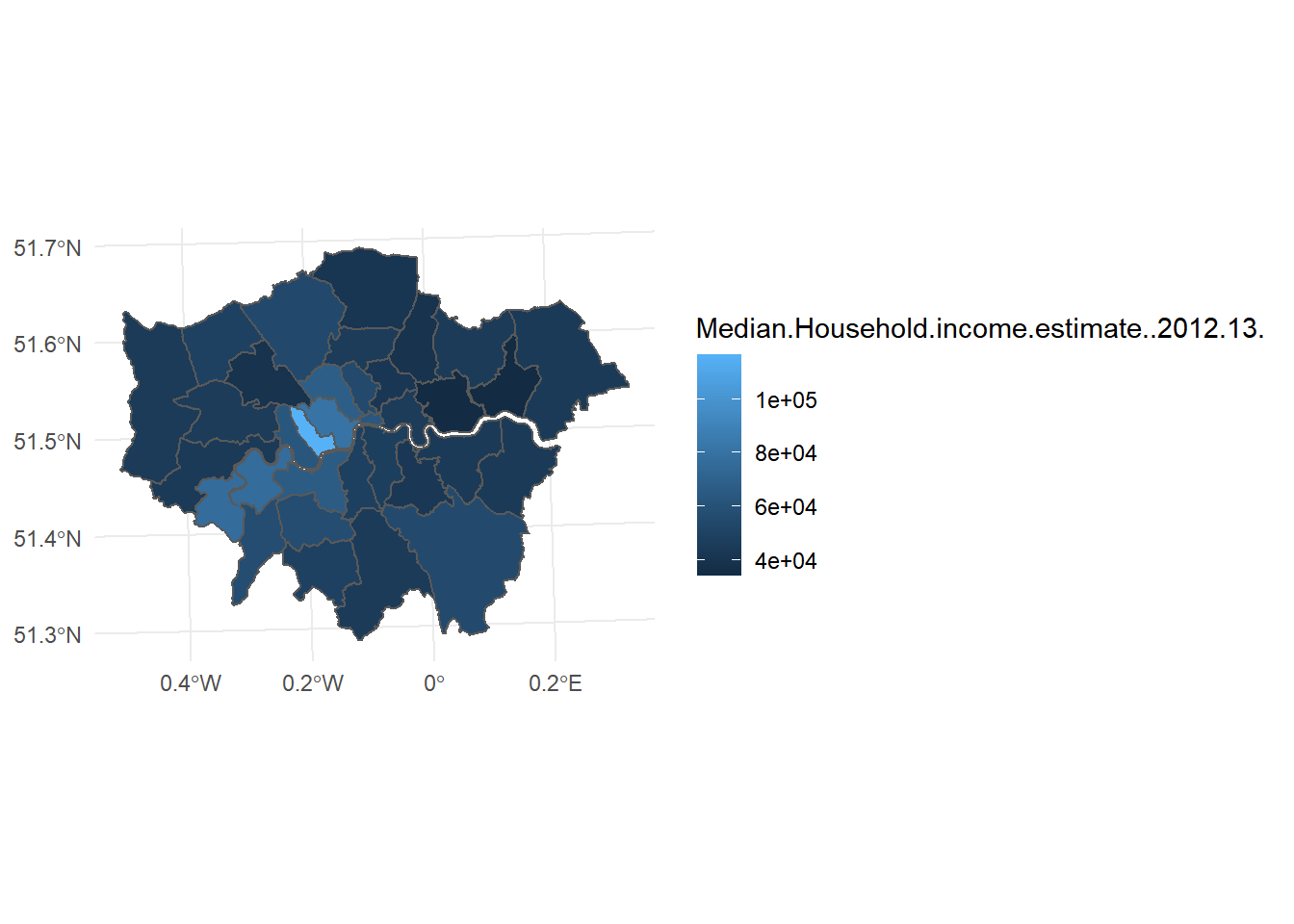
- As you can see, this map looks OK, but there are a few issues with things like the colour ramp and a lack of appropriate labels. We can correct this by adding a few more layers. Firstly we can change the palette:
- And some appropriate labels:
- Before plotting the all of them together:
ggplot()+
geom_sf(mapping = aes(geometry=geometry,
fill = Median.Household.income.estimate..2012.13.)
,data = BoroughDataMap)+
theme_minimal()+
palette1+
labels
Check out this resource for more options in ggplot
2.6.1 Changing projections
Now until now, we’ve not really considered how our maps have been printed to the screen. The coordinates stored in the geometry column of your sf object contain the information to enable points, lines or polygons to be drawn on the screen. The first ggplot map above could fool you into thinking the coordinate system we are using is latitude and longitude, but actually, the map coordinates are stored in British National Grid.
How can we tell?
You can check that the coordinate reference systems of sf or sp objects using the print function:
## class : SpatialPolygonsDataFrame
## features : 33
## extent : 503568.2, 561957.5, 155850.8, 200933.9 (xmin, xmax, ymin, ymax)
## crs : +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.999601272 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs +ellps=airy +towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894
## variables : 74
## names : NAME, GSS_CODE, HECTARES, NONLD_AREA, ONS_INNER, SUB_2009, SUB_2006, Ward.name, Old.code, New.code, Population...2015, Children.aged.0.15...2015, Working.age..16.64....2015, Older.people.aged.65....2015, X..All.Children.aged.0.15...2015, ...
## min values : Barking and Dagenham, E09000001, 314.942, 0, F, NA, NA, Barking and Dagenham, 00AA, E09000001, 8100, 650, 6250, 1250, 8, ...
## max values : Westminster, E09000033, 15013.487, 370.619, T, NA, NA, Westminster, 00BK, E09000033, 393200, 82900, 257850, 56550, 26.1, ...## Simple feature collection with 33 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 503568.2 ymin: 155850.8 xmax: 561957.5 ymax: 200933.9
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.999601272 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs
## First 10 features:
## NAME GSS_CODE HECTARES NONLD_AREA ONS_INNER SUB_2009
## 1 Kingston upon Thames E09000021 3726.117 0.000 F <NA>
## 2 Croydon E09000008 8649.441 0.000 F <NA>
## 3 Bromley E09000006 15013.487 0.000 F <NA>
## 4 Hounslow E09000018 5658.541 60.755 F <NA>
## 5 Ealing E09000009 5554.428 0.000 F <NA>
## 6 Havering E09000016 11445.735 210.763 F <NA>
## 7 Hillingdon E09000017 11570.063 0.000 F <NA>
## 8 Harrow E09000015 5046.330 0.000 F <NA>
## 9 Brent E09000005 4323.270 0.000 F <NA>
## 10 Barnet E09000003 8674.837 0.000 F <NA>
## SUB_2006 geometry
## 1 <NA> MULTIPOLYGON (((516401.6 16...
## 2 <NA> MULTIPOLYGON (((535009.2 15...
## 3 <NA> MULTIPOLYGON (((540373.6 15...
## 4 <NA> MULTIPOLYGON (((521975.8 17...
## 5 <NA> MULTIPOLYGON (((510253.5 18...
## 6 <NA> MULTIPOLYGON (((549893.9 18...
## 7 <NA> MULTIPOLYGON (((510599.8 19...
## 8 <NA> MULTIPOLYGON (((510599.8 19...
## 9 <NA> MULTIPOLYGON (((525201 1825...
## 10 <NA> MULTIPOLYGON (((524579.9 19...2.6.1.1 Proj4
If you’re a spatial geek and you’re used to looking at London, then a quick glance at the values of the extent / bounding box (bbox) will tell you that you are working in British National Grid as the x and y values are in 6 Figures, with x values around 52000 to 55000 and y values around 15000 to 20000. The other way of telling is by looking at the coordinate reference system (CRS) value — in the files above it’s defined by the bit that says:
+proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +ellps=airy
“Well that’s clear as mud!” I hear you cry! Yes, not obvious is it! This is called a proj-string or proj4-string and its the proj4-string for British National Grid. You can learn what each of the bits of this mean here
The proj4-string basically tells the computer where on the earth to locate the coordinates that make up the geometries in your file and what distortions to apply (i.e. if to flatten it out completely etc.)
- Sometimes you can download data from the web and it doesn’t have a CRS . If any boundary data you download does not have a coordinate reference system attached to it (NA is displayed in the coord. ref section), this is not a huge problem — it can be added afterwards by adding the proj4string to the file.
To find the proj4-strings for a whole range of different geographic projections, use the search facility at http://spatialreference.org/ or http://epsg.io/.
2.6.1.2 EPSG
Now, if you can store a whole proj4-string in your mind, you must be some kind of savant (why are you doing this course? you could make your fortune as a card-counting poker player or something!). The rest of us need something a little bit more easy to remember and for coordinate reference systems, the saviour is the European Petroleum Survey Group (EPSG) — (naturally!). Now managed and maintained by the International Association of Oil and Gas producers — EPSG codes are short numbers represent all coordinate reference systems in the world and link directly to proj4 strings.
The EPSG code for British National Grid is 27700 — http://epsg.io/27700. The EPSG code for the WGS84 World Geodetic System (usually the default CRS for most spatial data) is 4326 — http://epsg.io/4326
- If your boundary data doesn’t have a spatial reference system, you can read it in you can read it in and set the projection either with the full proj4 string, or, more easily, with the EPSG code:
# read borough map in and explicitly set projection to British National Grid
# using the EPSG string code 27700
BoroughMapSF <- st_read("prac1_data/statistical-gis-boundaries-london/ESRI/London_Borough_Excluding_MHW.shp") ## Reading layer `London_Borough_Excluding_MHW' from data source `C:\Users\Andy\OneDrive - University College London\Teaching\CASA0005repo\prac1_data\statistical-gis-boundaries-london\ESRI\London_Borough_Excluding_MHW.shp' using driver `ESRI Shapefile'
## Simple feature collection with 33 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 503568.2 ymin: 155850.8 xmax: 561957.5 ymax: 200933.9
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.999601272 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs#or more concisely
BoroughMapSF <- st_read("prac1_data/statistical-gis-boundaries-london/ESRI/London_Borough_Excluding_MHW.shp") %>% st_set_crs(27700)## Reading layer `London_Borough_Excluding_MHW' from data source `C:\Users\Andy\OneDrive - University College London\Teaching\CASA0005repo\prac1_data\statistical-gis-boundaries-london\ESRI\London_Borough_Excluding_MHW.shp' using driver `ESRI Shapefile'
## Simple feature collection with 33 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: 503568.2 ymin: 155850.8 xmax: 561957.5 ymax: 200933.9
## epsg (SRID): NA
## proj4string: +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.999601272 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs- Another option is to use the function
readOGR()from thergdalpackage:
## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Andy\OneDrive - University College London\Teaching\CASA0005repo\prac1_data\statistical-gis-boundaries-london\ESRI\London_Borough_Excluding_MHW.shp", layer: "London_Borough_Excluding_MHW"
## with 33 features
## It has 7 fields#create a variable for the EPSG code to reference the proj4string
#(EPSG codes are shorter and easier to remember than the full strings!)
#and store it in a variable...
UKBNG <- "+init=epsg:27700"
#now set the proj4string for your BoroughMap object
#note, this will probably throw an error if your dataset already has a
#CRS, this is just for demonstration...
proj4string(BoroughMapSP) <- CRS(UKBNG)## class : SpatialPolygonsDataFrame
## features : 33
## extent : 503568.2, 561957.5, 155850.8, 200933.9 (xmin, xmax, ymin, ymax)
## crs : +init=epsg:27700 +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs +ellps=airy +towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894
## variables : 7
## names : NAME, GSS_CODE, HECTARES, NONLD_AREA, ONS_INNER, SUB_2009, SUB_2006
## min values : Barking and Dagenham, E09000001, 314.942, 0, F, NA, NA
## max values : Westminster, E09000033, 15013.487, 370.619, T, NA, NA2.6.1.3 Reprojecting your spatial data
Reprojecting your data is something that you might have to (or want to) do, on occasion. Why? Well, one example might be if you want to measure the distance of a line object, or the distance between two polygons. This can be done far more easily in a projected coordinate system like British National Grid (where the units are measured in metres) than it can a geographic coordinate system such as WGS84 (where the units are degrees).
For generating maps in packages like leaflet, your maps will also need to be in WGS84, rather than British National Grid.
- So once your data has a coordinates system to work with, we can re-project or transform to anything we like. The most commonly used is the global latitude and longitude system (WGS84). With SP objects, this is carried out using the
spTransform()function:
BoroughMapSPWGS84 <-spTransform(BoroughMapSP, CRS("+proj=longlat +datum=WGS84"))
print(BoroughMapSPWGS84)## class : SpatialPolygonsDataFrame
## features : 33
## extent : -0.5103751, 0.3340155, 51.28676, 51.69187 (xmin, xmax, ymin, ymax)
## crs : +proj=longlat +datum=WGS84 +ellps=WGS84 +towgs84=0,0,0
## variables : 7
## names : NAME, GSS_CODE, HECTARES, NONLD_AREA, ONS_INNER, SUB_2009, SUB_2006
## min values : Barking and Dagenham, E09000001, 314.942, 0, F, NA, NA
## max values : Westminster, E09000033, 15013.487, 370.619, T, NA, NA#transform it back again:
BoroughMapSPBNG <-spTransform(BoroughMapSP, CRS(UKBNG))
print(BoroughMapSPBNG)## class : SpatialPolygonsDataFrame
## features : 33
## extent : 503568.2, 561957.5, 155850.8, 200933.9 (xmin, xmax, ymin, ymax)
## crs : +init=epsg:27700 +proj=tmerc +lat_0=49 +lon_0=-2 +k=0.9996012717 +x_0=400000 +y_0=-100000 +datum=OSGB36 +units=m +no_defs +ellps=airy +towgs84=446.448,-125.157,542.060,0.1502,0.2470,0.8421,-20.4894
## variables : 7
## names : NAME, GSS_CODE, HECTARES, NONLD_AREA, ONS_INNER, SUB_2009, SUB_2006
## min values : Barking and Dagenham, E09000001, 314.942, 0, F, NA, NA
## max values : Westminster, E09000033, 15013.487, 370.619, T, NA, NAAnd for SF objects it’s carried out using st_transform:
## Simple feature collection with 33 features and 7 fields
## geometry type: MULTIPOLYGON
## dimension: XY
## bbox: xmin: -0.5103751 ymin: 51.28676 xmax: 0.3340156 ymax: 51.69187
## epsg (SRID): 4326
## proj4string: +proj=longlat +datum=WGS84 +no_defs
## First 10 features:
## NAME GSS_CODE HECTARES NONLD_AREA ONS_INNER SUB_2009
## 1 Kingston upon Thames E09000021 3726.117 0.000 F <NA>
## 2 Croydon E09000008 8649.441 0.000 F <NA>
## 3 Bromley E09000006 15013.487 0.000 F <NA>
## 4 Hounslow E09000018 5658.541 60.755 F <NA>
## 5 Ealing E09000009 5554.428 0.000 F <NA>
## 6 Havering E09000016 11445.735 210.763 F <NA>
## 7 Hillingdon E09000017 11570.063 0.000 F <NA>
## 8 Harrow E09000015 5046.330 0.000 F <NA>
## 9 Brent E09000005 4323.270 0.000 F <NA>
## 10 Barnet E09000003 8674.837 0.000 F <NA>
## SUB_2006 geometry
## 1 <NA> MULTIPOLYGON (((-0.330679 5...
## 2 <NA> MULTIPOLYGON (((-0.0640212 ...
## 3 <NA> MULTIPOLYGON (((0.01213098 ...
## 4 <NA> MULTIPOLYGON (((-0.2445624 ...
## 5 <NA> MULTIPOLYGON (((-0.4118326 ...
## 6 <NA> MULTIPOLYGON (((0.1586929 5...
## 7 <NA> MULTIPOLYGON (((-0.4040719 ...
## 8 <NA> MULTIPOLYGON (((-0.4040719 ...
## 9 <NA> MULTIPOLYGON (((-0.1965687 ...
## 10 <NA> MULTIPOLYGON (((-0.1998964 ...In the SF object, you can compare the values in the geometry column with those in the original file to look at how they have changed…
2.6.2 Maps with extra features
Now we can re-project our data, it frees us up to bring in, for example, different base maps and other stuff…
How about adding a basemap to our map…this follows on from the earlier section (when i said read_osm() wasn’t working) and builds on what we just learned about mapping with ggplot
library(ggmap)
library(BAMMtools)
# put into WGS84 to get basemap data
BoroughDataMapWGS84<-st_transform(BoroughDataMap, 4326)
# bounding box of London
londonbbox2 <- as.vector(st_bbox(BoroughDataMapWGS84))
# use bounding box to get our basemap
b <- get_map(londonbbox2,
maptype="roadmap",
source="osm",
zoom=10)
plot(b)
# try changing the maptype to watercolor
b <- get_stamenmap(londonbbox2,
zoom = 10,
source="osm",
maptype = "toner-lite")
plot(b)
# work out the jenks of our data, k means numnber of divisons
jenks=getJenksBreaks(BoroughDataMapWGS84$Rate.of.JobSeekers.Allowance..JSA..Claimants...2015,
k=5)
# set the palette using colorbrewer
palette1<- scale_fill_distiller(type = "seq",
palette = "YlOrBr",
breaks=jenks,
guide="legend")
# any labels
labels<-labs(title="Rate per 1,000 people",
x="Longitude",
y="Latitude")
# use the basemap then add our other data
map<-ggmap::ggmap(b) +
geom_sf(data = BoroughDataMapWGS84,
aes(geometry=geometry,
fill=Rate.of.JobSeekers.Allowance..JSA..Claimants...2015),
alpha=0.5,
inherit.aes = FALSE)+
theme_minimal()+
palette1+
labels+
guides(fill=guide_legend(title="JSA"))
plot(map)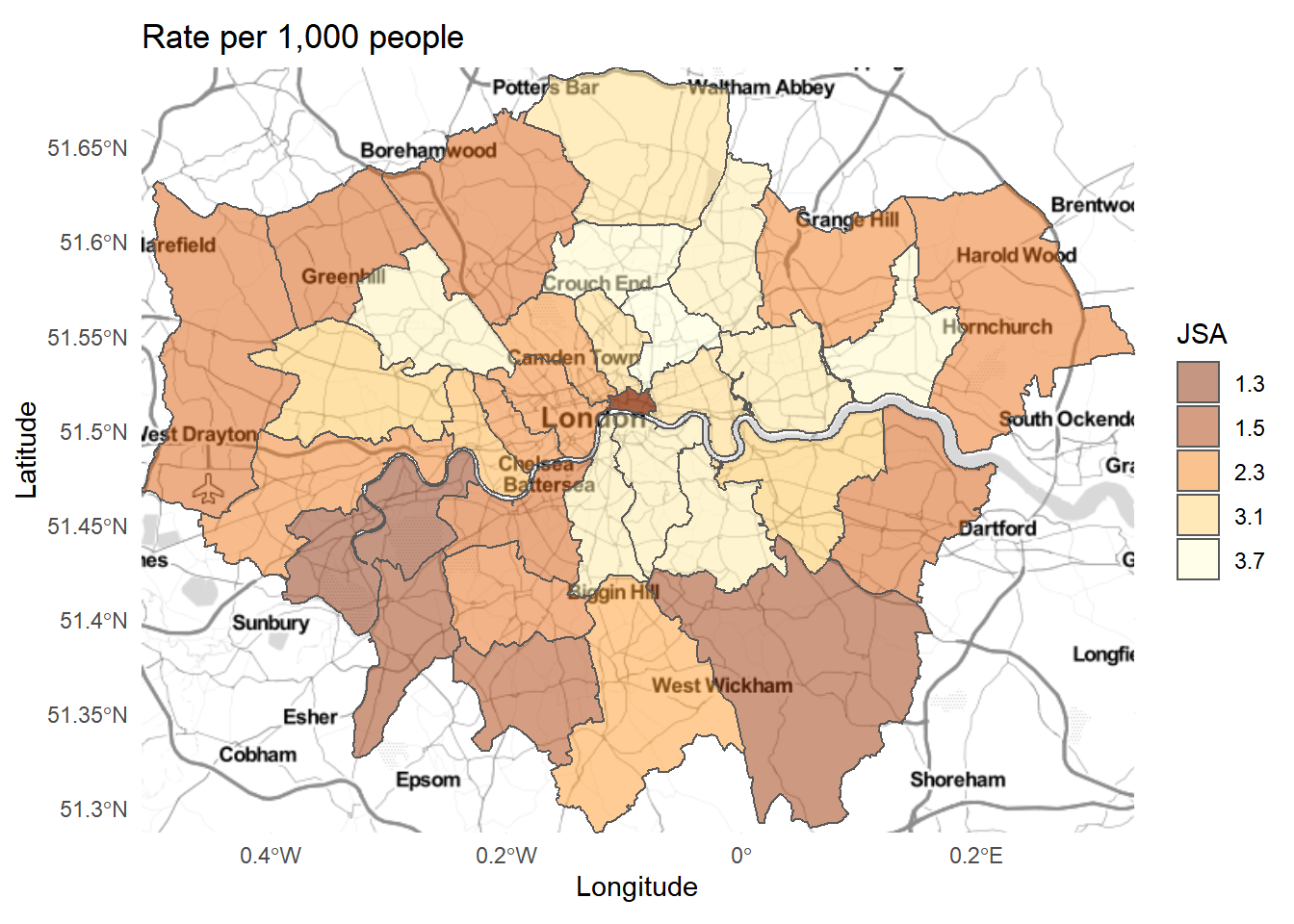
2.6.3 Extension
2.6.3.1 Faceted plots
One of the nice features of ggplot2 is its faceting function which allows you to lay out subsets of your data in different panels of a grid.
See if you can create a faceted grid of London maps like the one shown below. To do this, you will need to go through several stages:
You will might need to subset your data frame so that it only contains data on the same scale (you have a number of columns that counts and area, for example) –– you can show facets on different scales, but we will leave this for the time being (this code is not shown here).
You will also need to make sure your subset includes a few columns of key ID information data at the beginning –– e.g. ID and geometry.
You will then need to use the
reshape2package to reformat your data using themelt()function, with an argument to specify the columns where your ID data ends (all columns afterwards containing data you want to plot). Use melt to bung all of the variables into a single column on top of each other, but leave out the geometry column or it will throw an error. Make sure you know which coloumn holds the geometry.I’m only going to select 10 coloumns of data here (measure.vars=10:20)…a call something like:
##
## Attaching package: 'reshape2'## The following object is masked from 'package:tidyr':
##
## smithsHave a look at borough_melt now — in this circumstance i find the best way is to click on the data in the enviroment window (top right), what do you notice?
#now join the geometry column back on
#you will have to join it along with all of the data again.
borough_melt <- left_join(borough_melt,BoroughDataMap,by = c("GSS_CODE" = "GSS_CODE"))
#here i'm removing everything except the variable coloumn,
#values and the geometry inforamtion
borough_melt <- borough_melt[,c(10:11,84)]
library(tmap)
library(sf)
library(maptools)
tmap_mode("plot")
borough_melt <- st_as_sf(borough_melt)
qtm(borough_melt, fill = "value", by = "variable")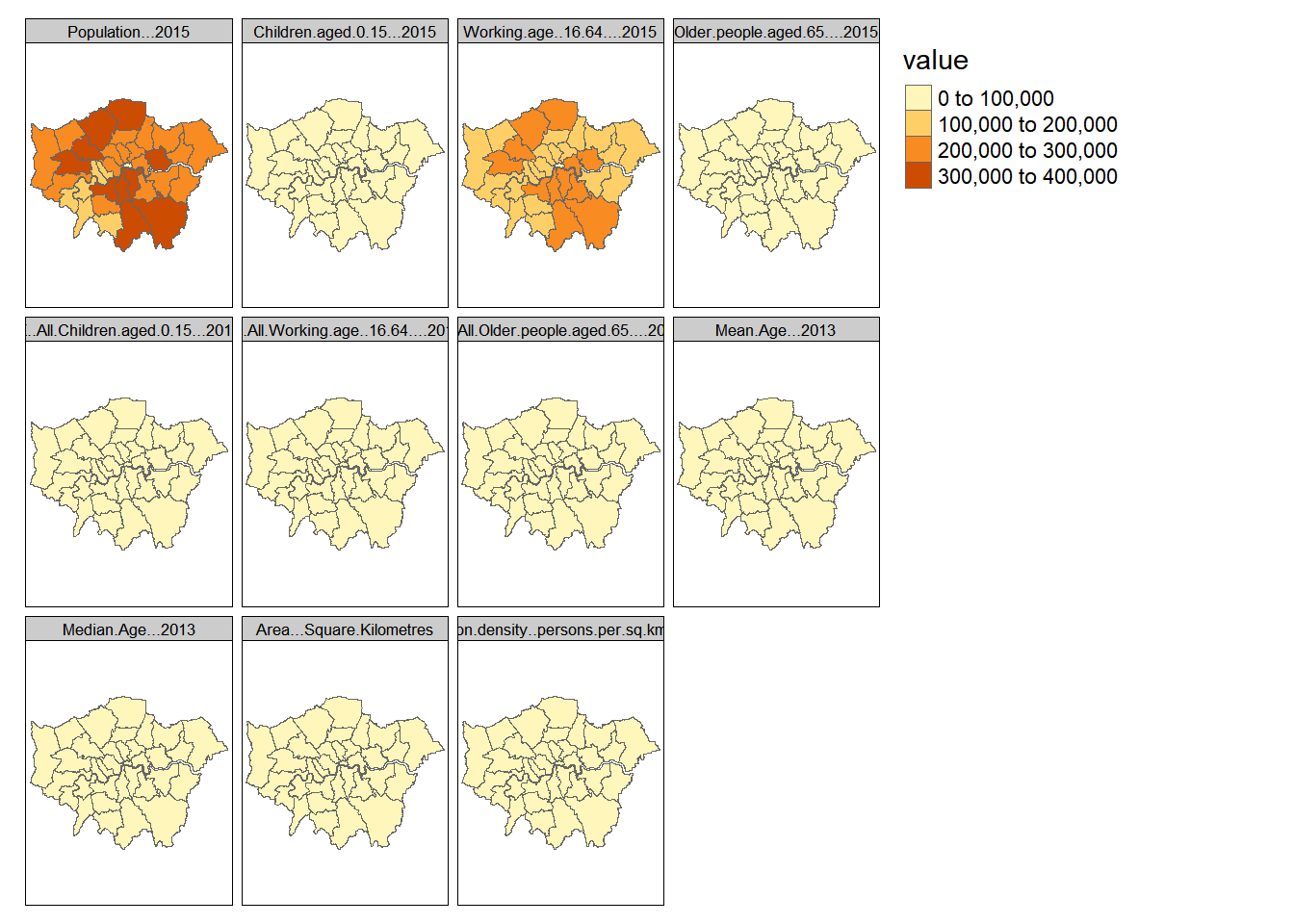
or, indeed, in ggplot2 like this:
ggplot()+
geom_sf(mapping = aes(geometry=geometry,
fill=value),
data = borough_melt)+
facet_wrap(~variable)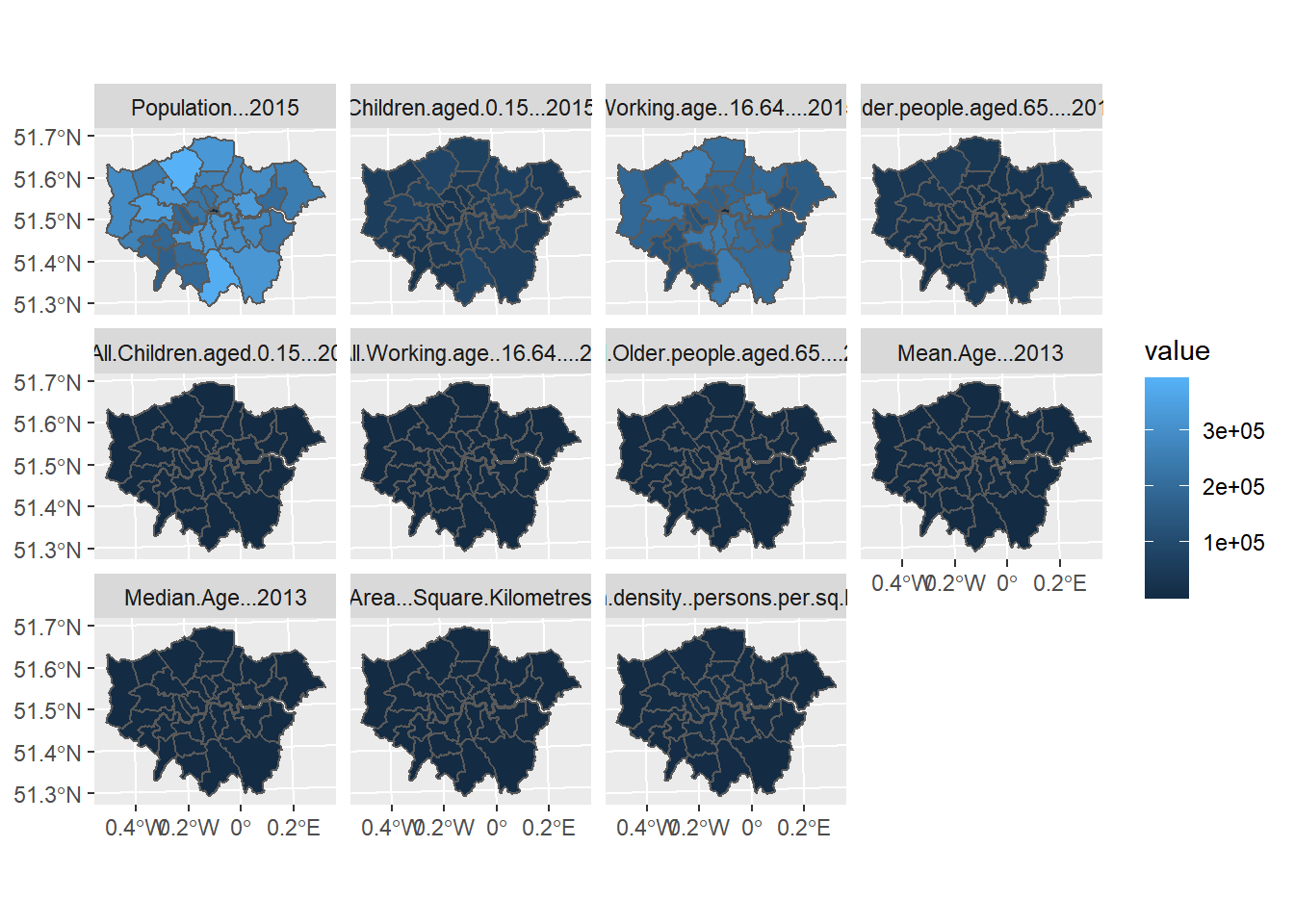
2.6.3.2 Interactive web maps
So we created an interactive map with tmap earlier and that was pretty cool, but if we want to do even more mind-blowing stuff later on in the course, we will need to get our heads around how to do interactive maps using leaflet.
Leaflet is a Java Script library for producing interactive web maps, and some enterprising coders over at RStudio have produced a package for allowing you to create your own Leaflet maps. All of the documentation for the R Leaflet package can be found here
library(sf)
library(sp)
library(magrittr)
library(classInt)
library(htmlTable)
library(htmltools)
library(htmlwidgets)
library(leaflet)2.6.3.2.1 Generating a colour ramp and palette
Before we create a leaflet map, we need to specify what the breaks in our data are going to be…
colours<- brewer.pal(5, "Blues")
breaks<-classIntervals(BoroughDataMap$Claimant.Rate.of.Housing.Benefit..2015.,
n=5,
style="jenks")
graphics::plot(breaks,
pal=colours)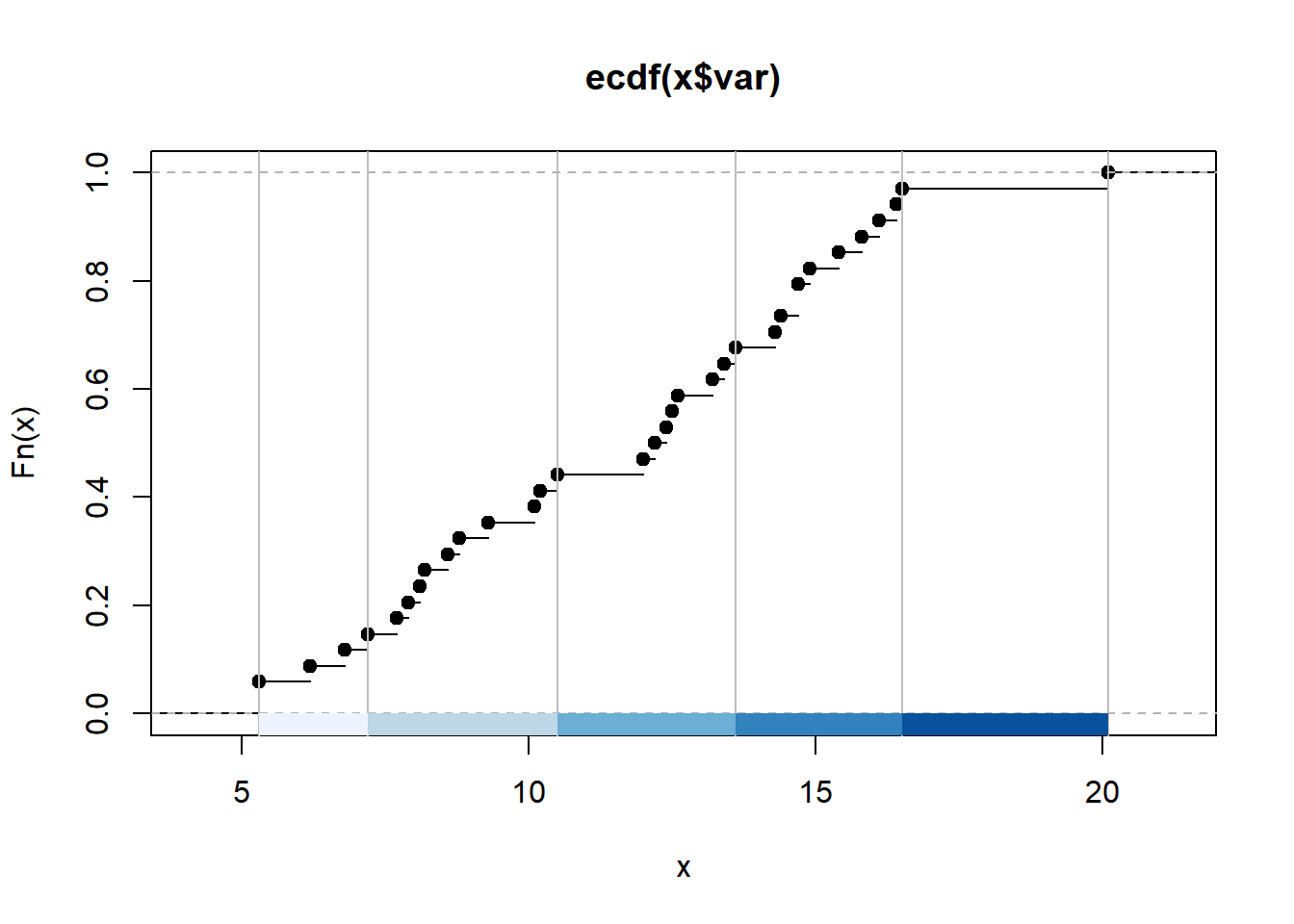
So we have now created a breaks object which uses the jenks natural breaks algorithm to divide up our variable into 5 classes. You will notice that breaks is a list of 2 objects. We want only the brks bit which contains the values for the breaks
## Length Class Mode
## var 34 -none- numeric
## brks 6 -none- numericNow we can create out leaflet interactive map.
Here you will see that I am using different syntax to that which has gone before. The %>% (pipe) operator is part of the magrittr package. magrittr is an entirely new way of thinking about R syntax. Read up on it if you wish, but for now it is useful to think of the pipe operator as simply meaning “then”. Do this THEN do this THEN do that.
2.6.3.2.2 Generating a colour ramp and palette
Before we create a leaflet map, we need to specify what the breaks in our data are going to be…
colours<- brewer.pal(5, "Blues")
breaks<-classIntervals(BoroughDataMap$Claimant.Rate.of.Housing.Benefit..2015.,
n=5,
style="jenks")
graphics::plot(breaks,
pal=colours)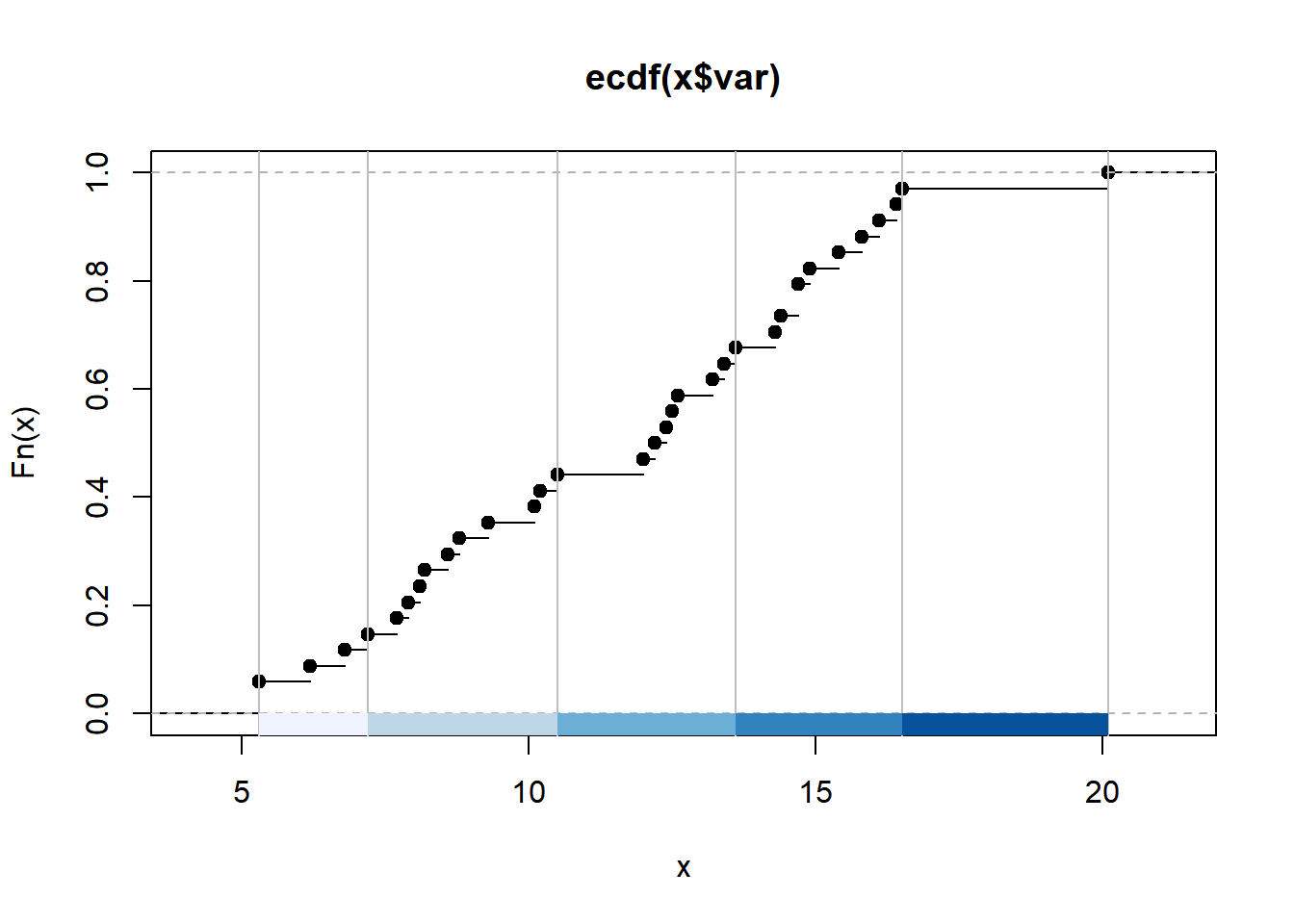
So we have now created a breaks object which uses the jenks natural breaks algorithm to divide up our variable into 5 classes. You will notice that breaks is a list of 2 objects. We want only the brks bit which contains the values for the breaks
## Length Class Mode
## var 34 -none- numeric
## brks 6 -none- numericNow we can create out leaflet interactive map.
Here you will see that I am using different syntax to that which has gone before. The %>% (pipe) operator is part of the magrittr package. magrittr is an entirely new way of thinking about R syntax. Read up on it if you wish, but for now it is useful to think of the pipe operator as simply meaning “then”. Do this THEN do this THEN do that.
# now, add some polygons colour them using your colour palette,
#overlay the, on top of a nice backdrop and add a legend.
#Note the use of the magrittr pipe operator (%>%)
#check the documentation to understand how this is working…
#create a new sp object from the earlier sf object
#with all of our data in THEN Transform it to WGS84
#THEN convert it to SP.
BoroughDataMapSP <- BoroughDataMap %>%
st_transform(crs = 4326) %>%
as("Spatial")
#create a colour palette using colorBin colour mapping
pal <- colorBin(palette = "YlOrRd",
domain = BoroughDataMapSP$Claimant.Rate.of.Housing.Benefit..2015.,
#create bins using the breaks object from earlier
bins = breaks)
prac2leaf <- leaflet(BoroughDataMapSP) %>%
addPolygons(stroke = FALSE,
fillOpacity = 0.5,
smoothFactor = 0.5,
color = ~pal(Claimant.Rate.of.Housing.Benefit..2015.),
popup = ~NAME
) %>%
addProviderTiles("CartoDB.DarkMatter") %>%
addLegend("bottomright",
pal= pal,
values = ~Claimant.Rate.of.Housing.Benefit..2015.,
title = "Housing Benefit Claimant Rate",
labFormat = labelFormat(prefix = "Per 1,000 people "),
opacity = 1
)2.7 Writing good R code
There are some basic principles to follow when writing code
- Use descriptive names for variaibles so you know what they are — this can be difficult especailly if you have multiple similar variables.
- Comment out parts you don’t need to run using #
- Provide regular comments for each part of your code. As you work through this practical book you should be able to find a small description of what each part of the code does. This is good practice as it not only helps you remember what your codes does, when you inevitably forget in the future, but also lets other understand and ‘read’ your code quicker.
- Use indents appropriately — this again greatly helps with readability and understanding. For example, what is easier to understand…this..
map<-ggmap::ggmap(b) +
geom_sf(data = BoroughDataMapWGS84,
aes(geometry=geometry,
fill=Rate.of.JobSeekers.Allowance..JSA..Claimants...2015),
alpha=0.5,
inherit.aes = FALSE)+
theme_minimal()+
palette1+
labels+
guides(fill=guide_legend(title="JSA"))
plot(map)or this…
2.8 Tidying data
In this practical we just showed how you to load, extract and reshape data using melt, however there is a better way to tidy data. As per the R for Data Science book, tidy data is defined using the following three rules:
Each variable must have its own column.
Each observation must have its own row.
Each value must have its own cell.
But, as per the book, these three are interrelated as you can’t only adhere to two without adhering to all three. So this gives us:
Put each dataset in a tibble
Put each variable in a column
Earlier we read in the data using:
But we can also do something like this to force the columns to the appopraite data types (e.g. text, numberic)
flytipping1 <- read_csv("https://data.london.gov.uk/download/fly-tipping-incidents/536278ff-a391-4f20-bc79-9e705c9b3ec0/fly-tipping-borough.csv",
col_types = cols(
code = col_character(),
area = col_character(),
year = col_character(),
total_incidents = col_number(),
total_action_taken = col_number(),
warning_letters = col_number(),
fixed_penalty_notices = col_number(),
statutory_notices = col_number(),
formal_cautions = col_number(),
injunctions = col_number(),
prosecutions = col_number()
))
# view the data
view(flytipping1)So we have a tibble with columns of each varaible (e.g. warning letters, total actions taken) where every row is a London borough. We want make sure that each observation has its own row…it doesn’t as in the first row here we have observations for total incidents and total actions taken etc…to do this we will use pivot_longer(). Make sure you have the most recent version of tidyverse if you get an error.
#convert the tibble into a tidy tibble
library(tidyverse)
flytipping_long <- flytipping1 %>% pivot_longer(
cols = 4:11,
names_to = "tipping_type",
values_to = "count"
)
# view the data
view(flytipping_long)Do you see the difference…this is classed as tidy data as every variable has a column, every observation has a row and every value has a cell.
You could also use this to do the same thing…
#an alternative which just pulls everything out into a single table
flytipping2 <- flytipping1[,1:4]But my advice would be to learn how to use the tidy tools!
Now let’s make it a bit more suitable for mapping with pivot_wider() by making coloumns for each year of each variable….in the original .csv we had a year coloumn that had values of 2011-2012 to 2017-2018, so if we wanted to map a specifc year we’d have to filter out the year then map. Here we can just alter the data from pivot_longer() using the year and tipping type…
Note, just because the data is considered tidy doesn’t mean it is directly appropriate for mapping. It might need to be tidy for analysis, such as where we used
melt()earlier on (you could replacemelt()with what we’ve shown you here) but for mapping you probably want something a bit different.
#pivot the tidy tibble into one that is suitable for mapping
flytipping_wide <- flytipping_long %>% pivot_wider(
id_cols = 1:2,
names_from = c(year,tipping_type),
names_sep = "_",
values_from = count
)
view(flytipping_wide)But what if you were just interested in a specific varaible and wanted the coloums to be each year of the data…again using pivot_wider()
You could now join this to the London borough .shp and produce a map…
What’s the take home from this? Basically always try to put your data into a certain format before doing further analysis on it as it will be easier for you to determine the right tools to select.
2.9 Feedback
Was anything that we explained unclear this week or was something really clear…let us know using the feedback form. It’s anonymous and we’ll use the responses to clear any issues up in the future / adapt the material.